はじめに
弊社では、形状をパラメトリックに変化させながら設計案を探索する場面が多くあります。
その際には、複数の性能や機能の間にあるトレードオフを踏まえつつ、より望ましい形状を見つけるために多目的最適化を用います。多目的最適化にはさまざまな手法が存在するため、問題の性質に応じて適切なアルゴリズムを選択することが重要です。
本記事では、多目的最適化手法の中でも NSGA-II に代表される進化型多目的最適化(Evolutionary Multiobjective Optimization: EMO)を取り上げます。
EMO は1980年代半ばに始まり、1990年代以降に発展してきた分野であり、現在では多目的最適化における代表的な手法群の一つとして広く利用されています。
EMO に含まれる手法は、どれも同じアルゴリズムで動作しているわけではありません。パレート支配に基づく手法、性能指標を直接用いる手法、問題を分解して扱う手法、参照点を用いて探索を誘導する手法など、解の選び方や多様性の保ち方には明確な違いがあります。そして、こうした違いが、解の分布、目的数が増えた場合の性能、計算時間といった挙動の差として現れます。
そこで本記事では、まず代表的な手法の考え方を整理した上で、複数のベンチマーク問題を用いてそれぞれの特徴を比較します。
これにより、単に優劣を述べるのではなく、どのような問題に対してどの手法が適しているのかを考えるための材料を整理し、手法選択の一助となることを目指します。
各手法の概要
進化型多目的最適化の分類の一例として以下のようなものがあります。
| 分類 | 代表的な手法 | 特徴 |
|---|---|---|
| パレート支配型 | NSGA-II, SPEA-II | 非劣解の優越関係に基づいて選択する |
| 指標ベース型 | HypE, SMS-EMOA, IBEA | ハイパーボリュームや ε 指標など、性能指標を直接最適化する |
| 分解ベース型 | MOEA/D, MOEA/D-DE | 多目的問題を複数の単一目的問題に分解して同時に最適化する |
| 参照点ベース型 | NSGA-III, RVEA | あらかじめ与えた参照点・参照方向に基づいて探索を誘導する |
上記で紹介した手法の大きな違いは、次世代に残す個体を選ぶ環境選択(environmental selection) にあります。多くの進化型多目的最適化では、交叉や突然変異によって生成された子個体と親個体を合わせた集団から、次世代集団を構成する個体を選びます。
各手法は環境選択の考え方が異なっており、その違いが収束性や多様性、計算コストに大きく影響します。そのため、まずは各手法の環境選択の特徴を中心に紹介します。
NSGA-II(パレート支配型)
Non-dominated Sorting Genetic Algorithm II [1]
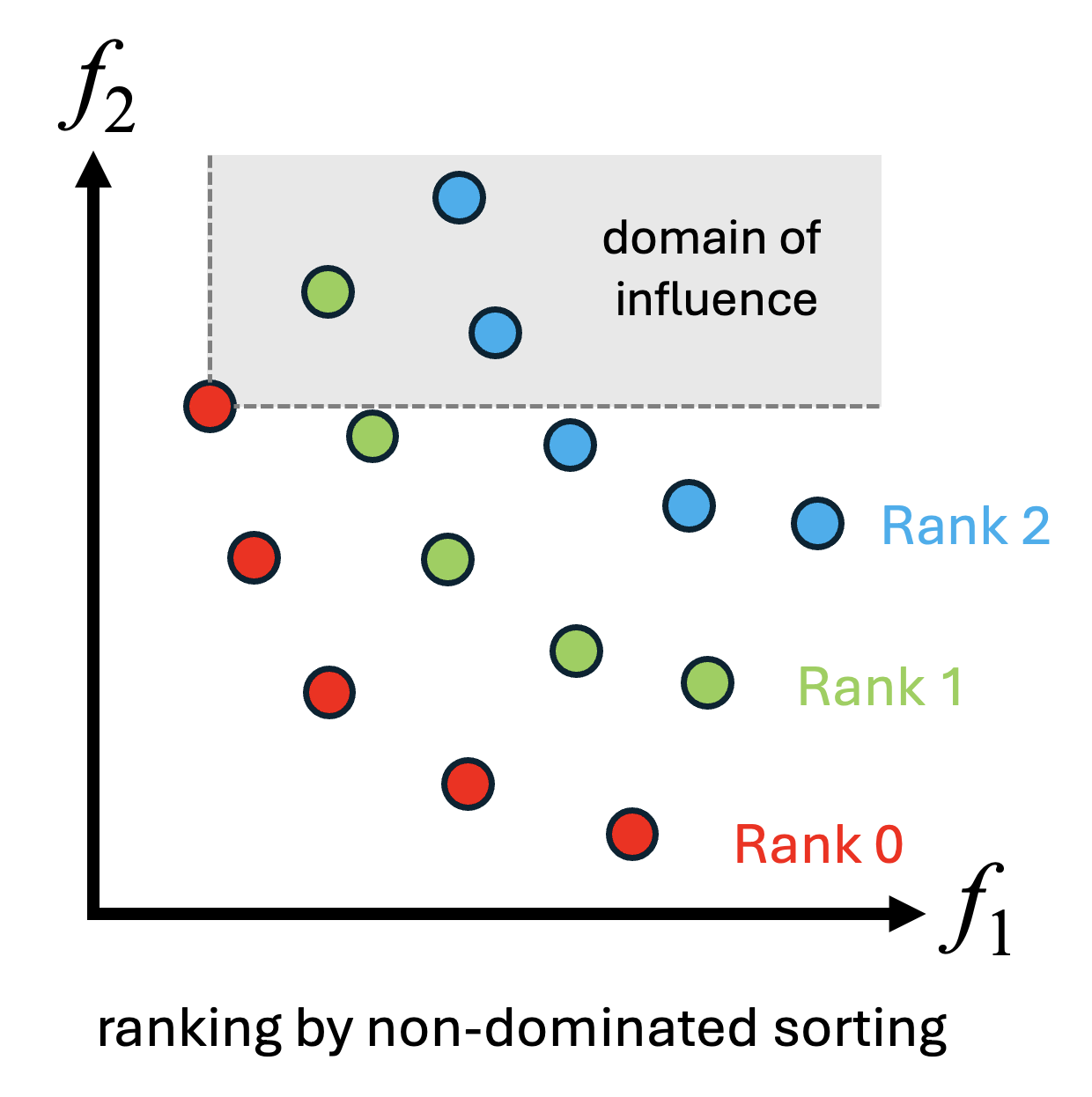
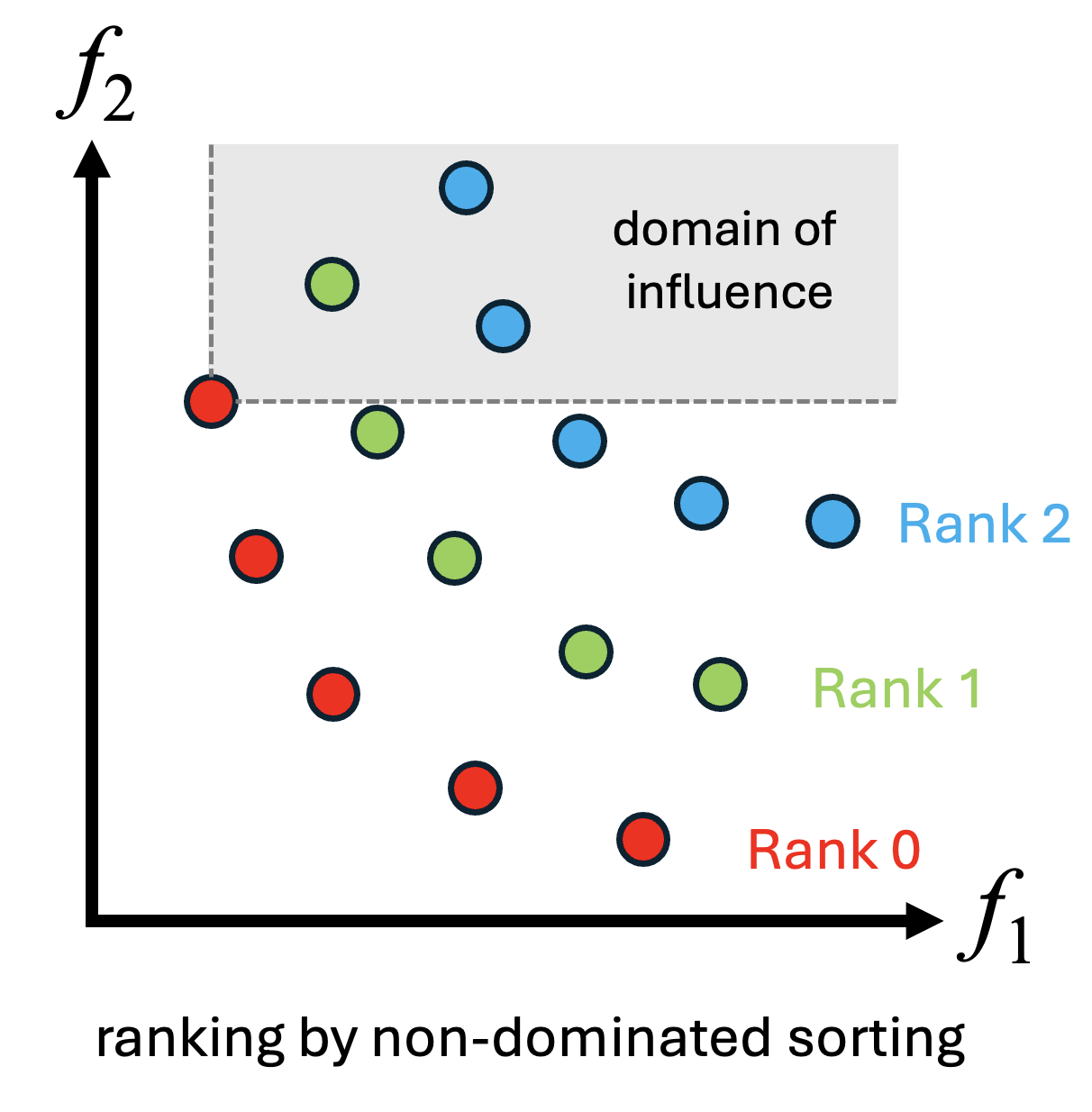
- 非支配ソート:すべての個体について目的関数値に基づく支配関係を計算し、どの個体にも支配されない個体群をランク0、ランク0を除いた集団でどの個体にも支配されない個体群をランク1として、順にランク付けを行います。
- この処理を非支配ソートといい、NSGA-II の NS に該当する部分です
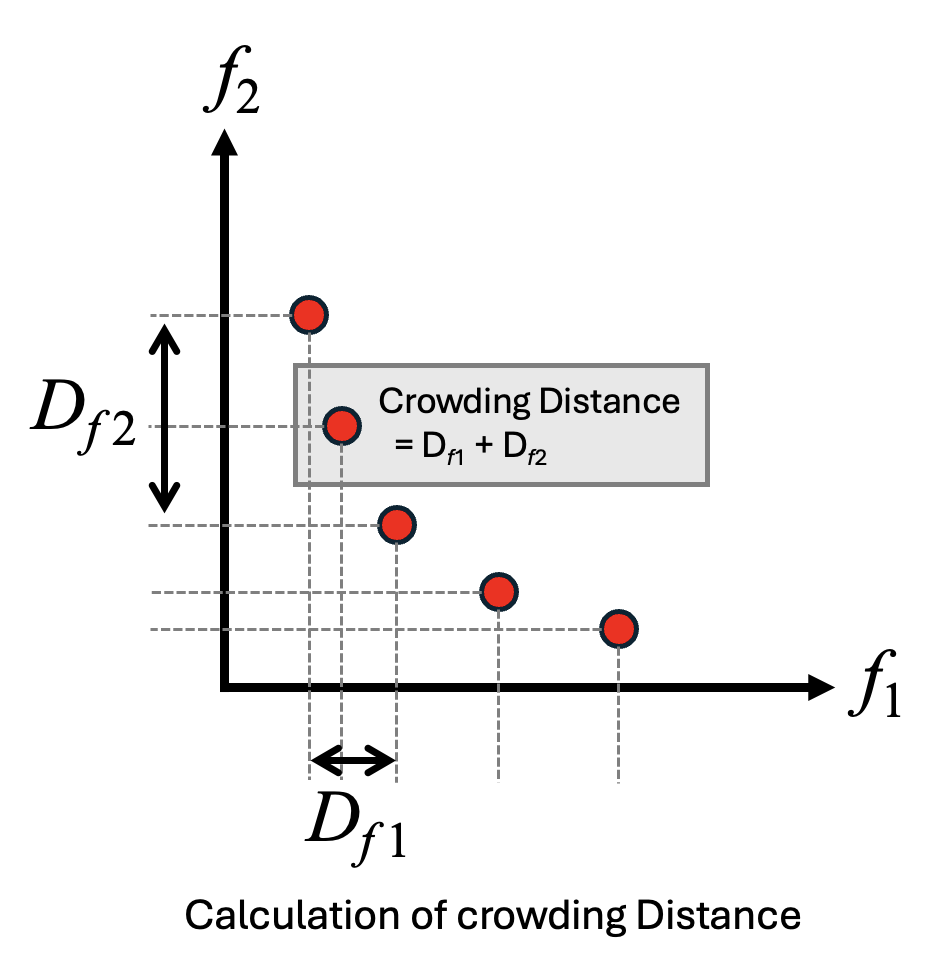
- 混雑距離の計算:同一ランク内では混雑距離を用いて多様性を評価します。
- 混雑距離は、各目的関数ごとに個体をソートし、前後の個体との目的関数値の差を集計することで求められます。
- 各目的関数における端点の個体は、混雑距離を無限大として扱います。
- 個体の選択:ランクが小さく、混雑距離が大きい個体ほど、次世代に残す個体として優先的に選択されます。
| Step 1 | Step 2 |
|---|---|
 |
 |
SPEA-II(パレート支配型)
Strength Pareto Evolution Algorithm II [2]
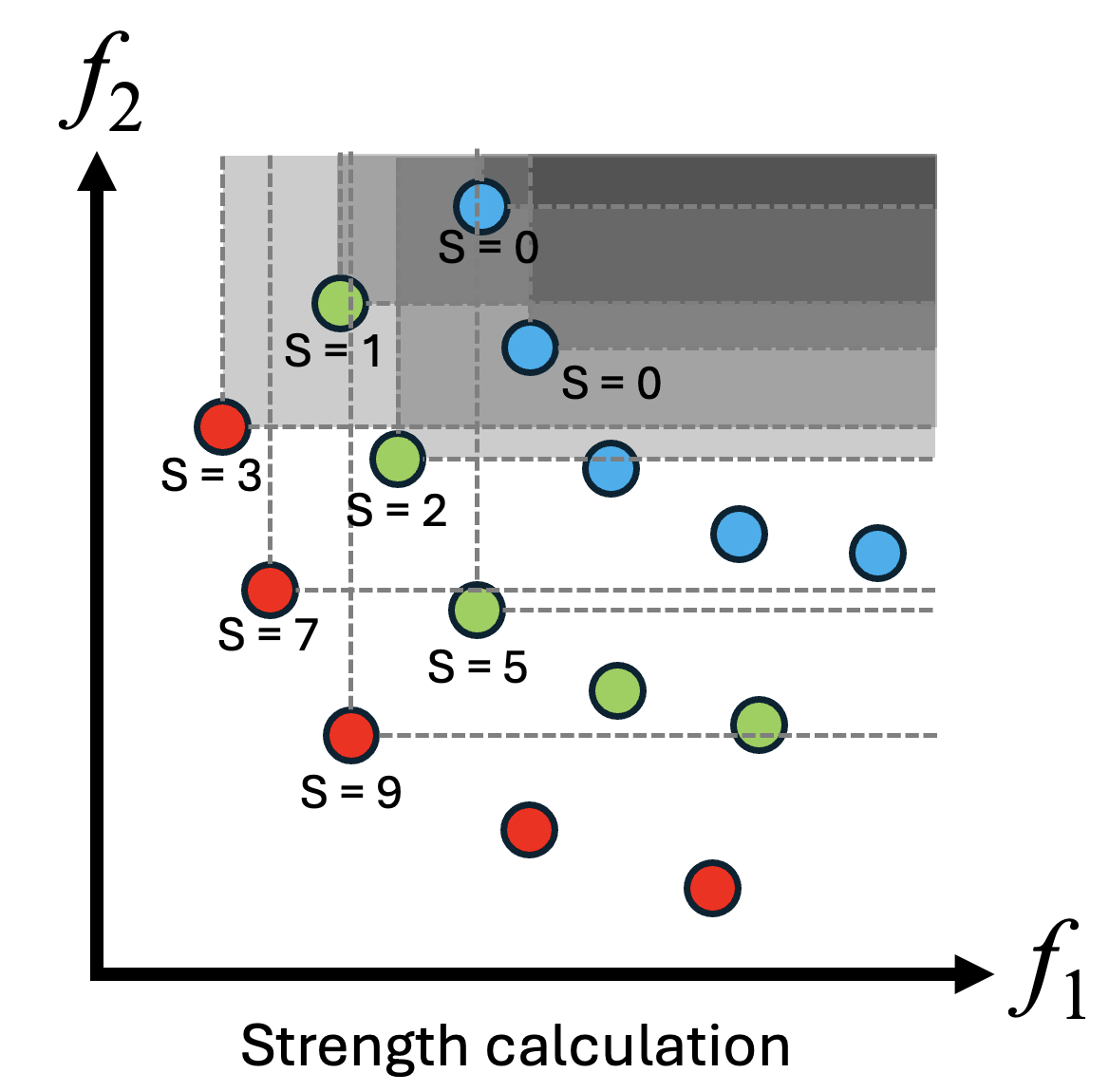
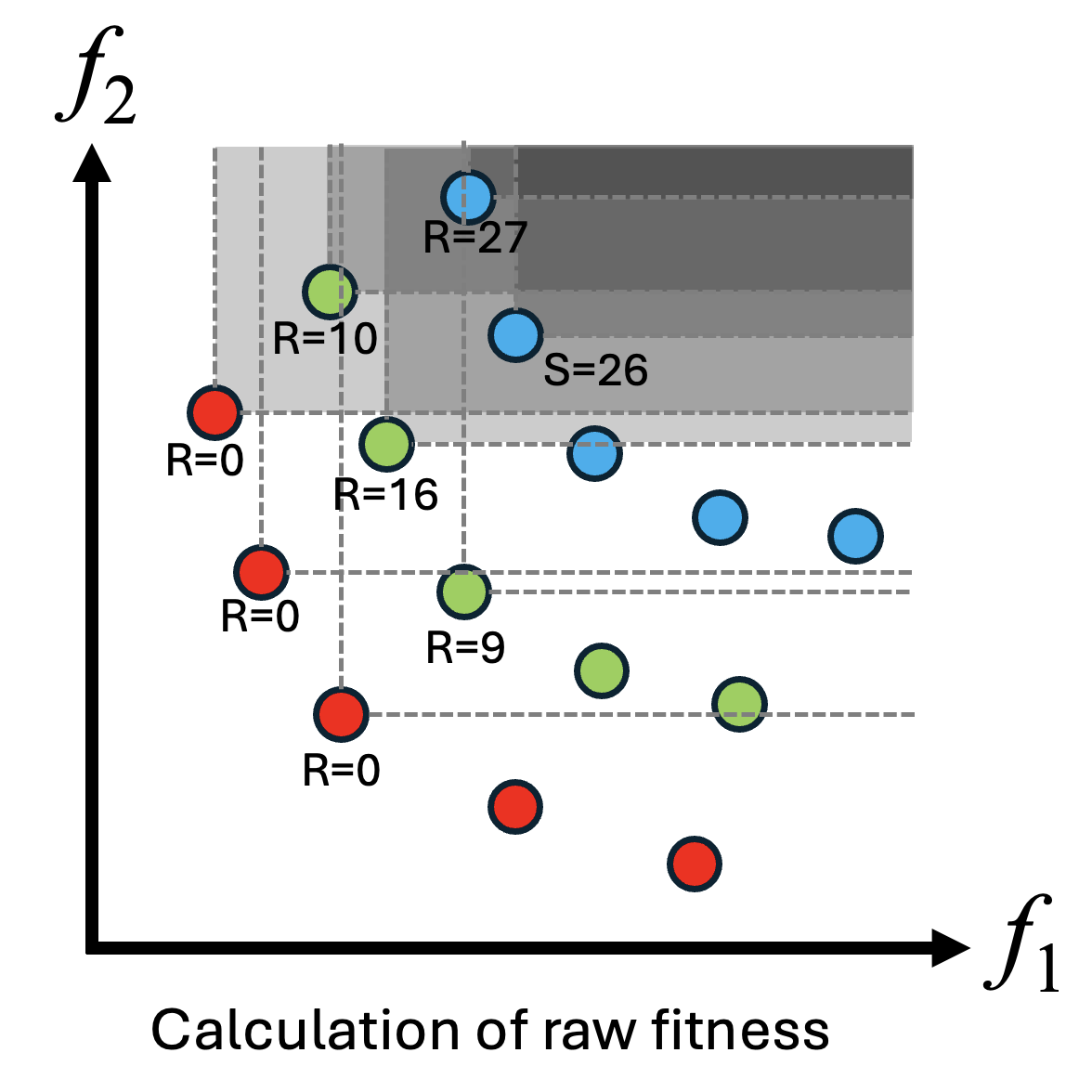
- 強度 \(S\) の計算:すべての個体を目的関数の値を対象にいくつの個体を支配するかの数を計算します。
- 生の適応度 \(R\) の計算:各個体に対して、その個体を支配している個体の強度\(S\)の総和を計算します。
- パレートフロントの個体は自分を支配している個体がないため0になり、NSGA-IIのランク0の個体と一致します。
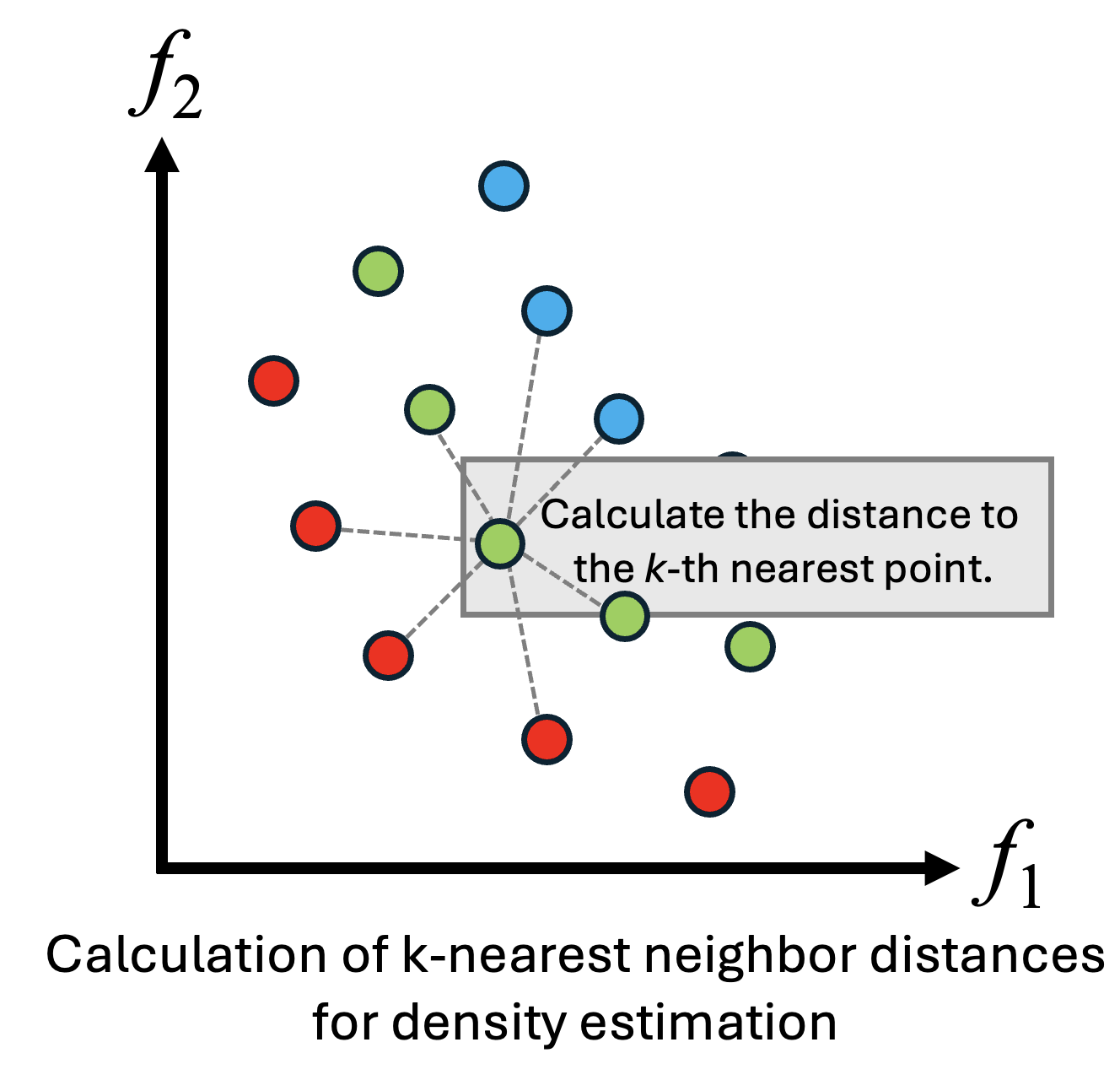
- 密度 D の計算: 多様性を評価するため、各個体の密度を \(k\) 近傍法で計算します。
- 密度\(D\)は対象個体の\(k\)番目に近い個体までの距離に2を足したものの逆数で求めることができ、0~0.5の範囲の値を取ります。
- 近くに個体がないほどこの値は小さくなります。
- 個体の選択:最終的な適応度は \(R+D\) によって計算し、この値が小さい個体ほど、次世代に残す個体として優先的に選択されます。
| Step 1 | Step2 |
|---|---|
 |
 |
| Step 3 | |
 |
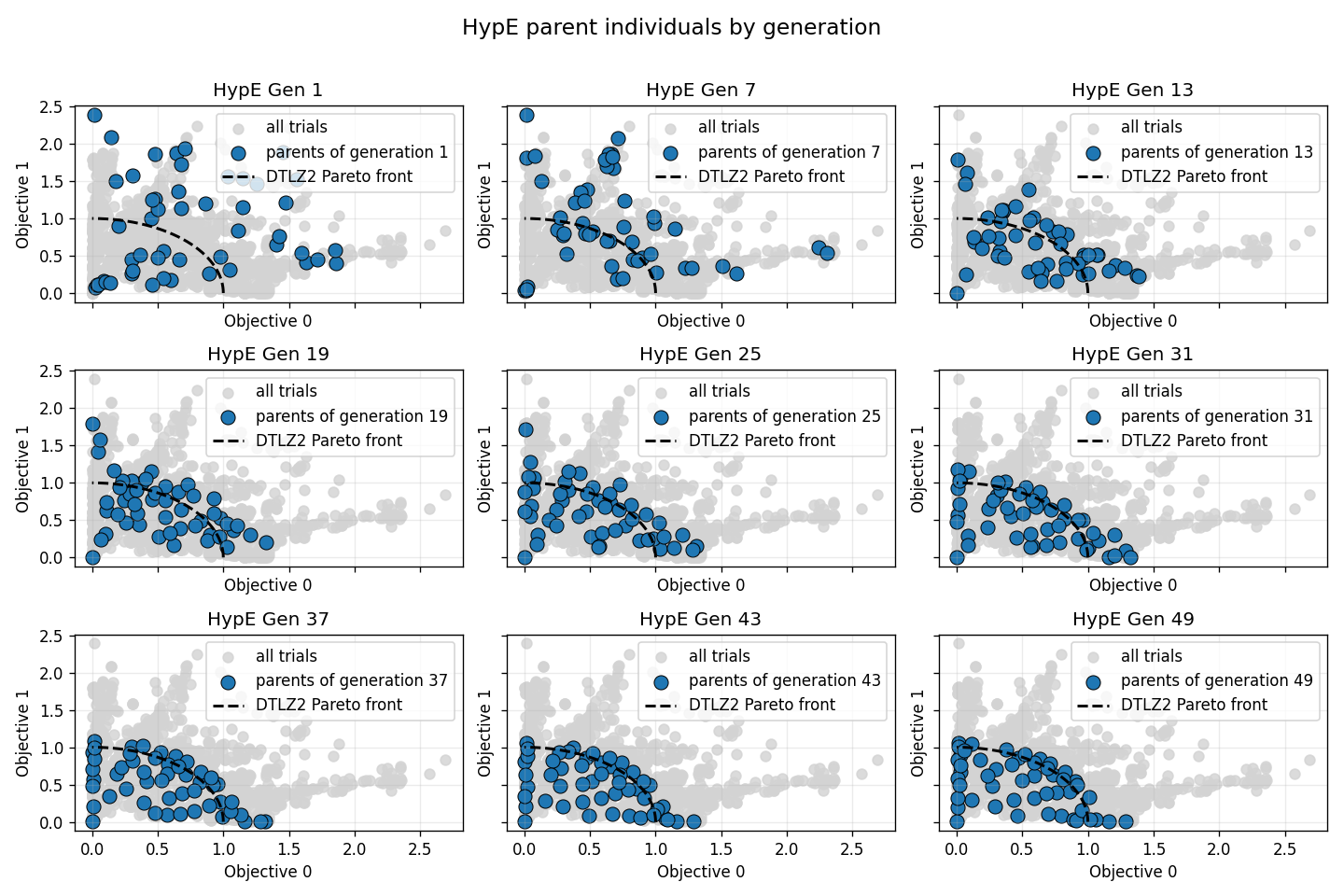
HypE(指標ベース支配型)
Hypervolume Estimation Algorithm [3]
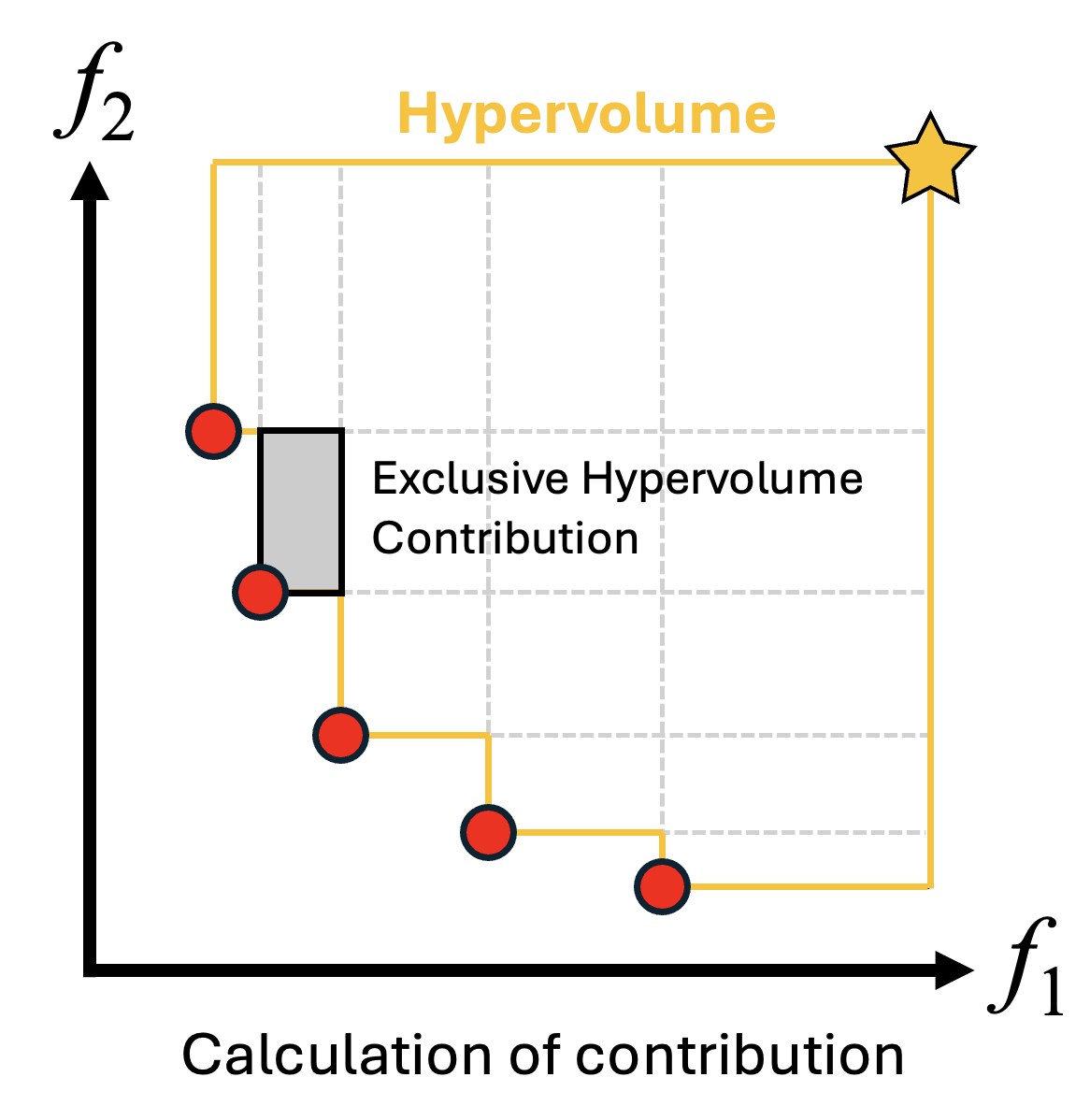
- 超体積貢献度の推定:各個体がハイパーボリュームにどの程度貢献しているかを評価します。
- 目的関数の数が増えると厳密なハイパーボリューム計算は高コストになるため、HypE ではモンテカルロサンプリングを用いて寄与を近似します。
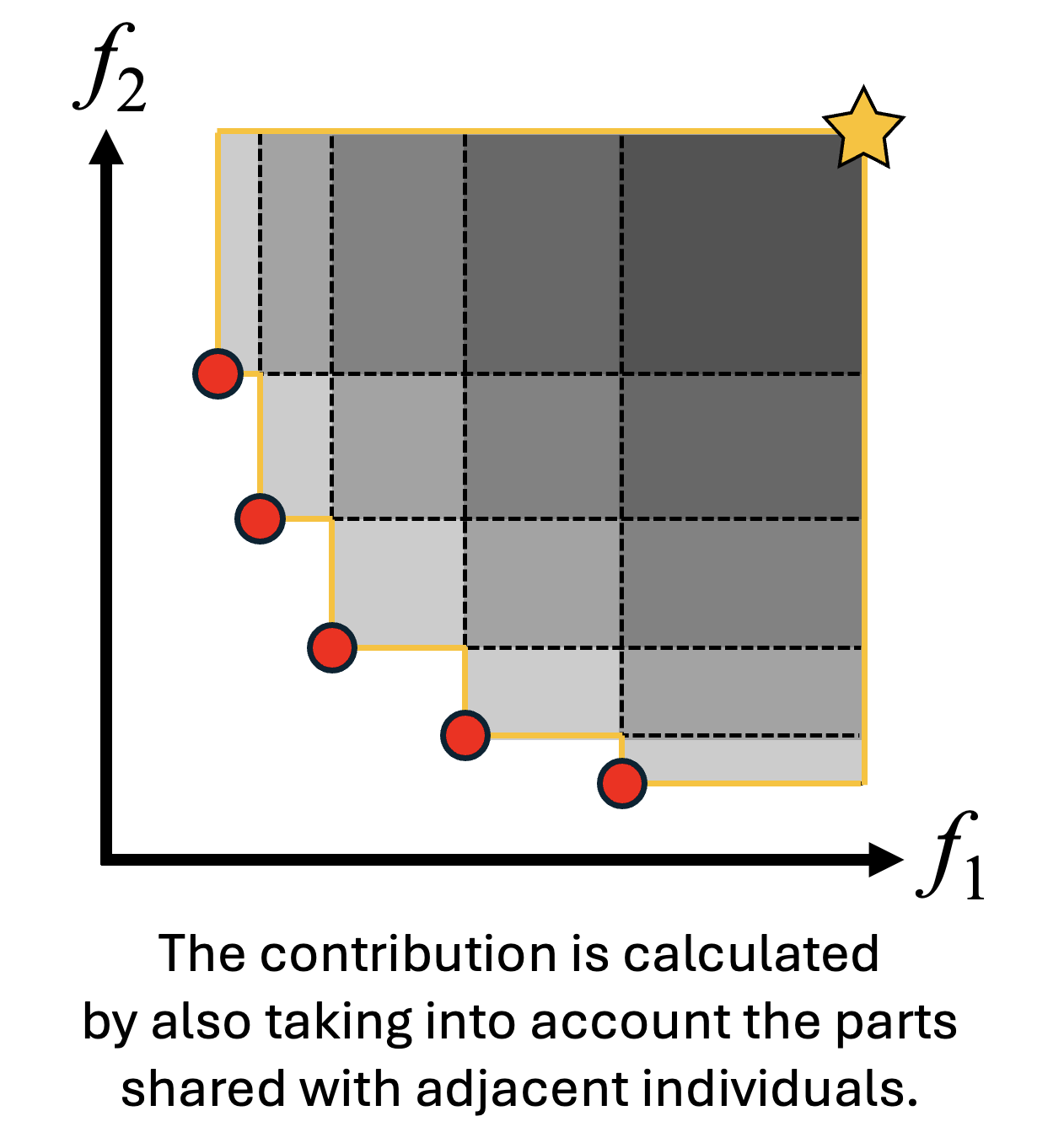
- 貢献度は他の個体と共有している部分について分割した貢献度として考慮されます。
- 適応度の計算:推定されたハイパーボリューム寄与に基づいて適応度を割り当てます。
- 他の個体ではカバーしにくい領域やフロント端部に位置する個体は、相対的に高く評価されやすくなります。
- ハイパーボリュームは「端の方にいる個体」や「周りに誰もいない領域の個体」を高く評価する性質があるため、自然と解の多様性が保たれます
- 個体の選択:ハイパーボリューム寄与の大きい個体ほど、次世代に残す個体として優先的に選択されます。
- 単一の指標で収束性と多様性を同時に評価できる点が特徴です。
| Step 1-1 | Step 1-2 |
|---|---|
 |
 |
NSGA-III(参照点ベース型)
Non-dominated Sorting Genetic Algorithm III [4]
- 非支配ソート:NSGA-IIと同様に、すべての個体を対象に非支配ソートを行い、ランク付けをします。
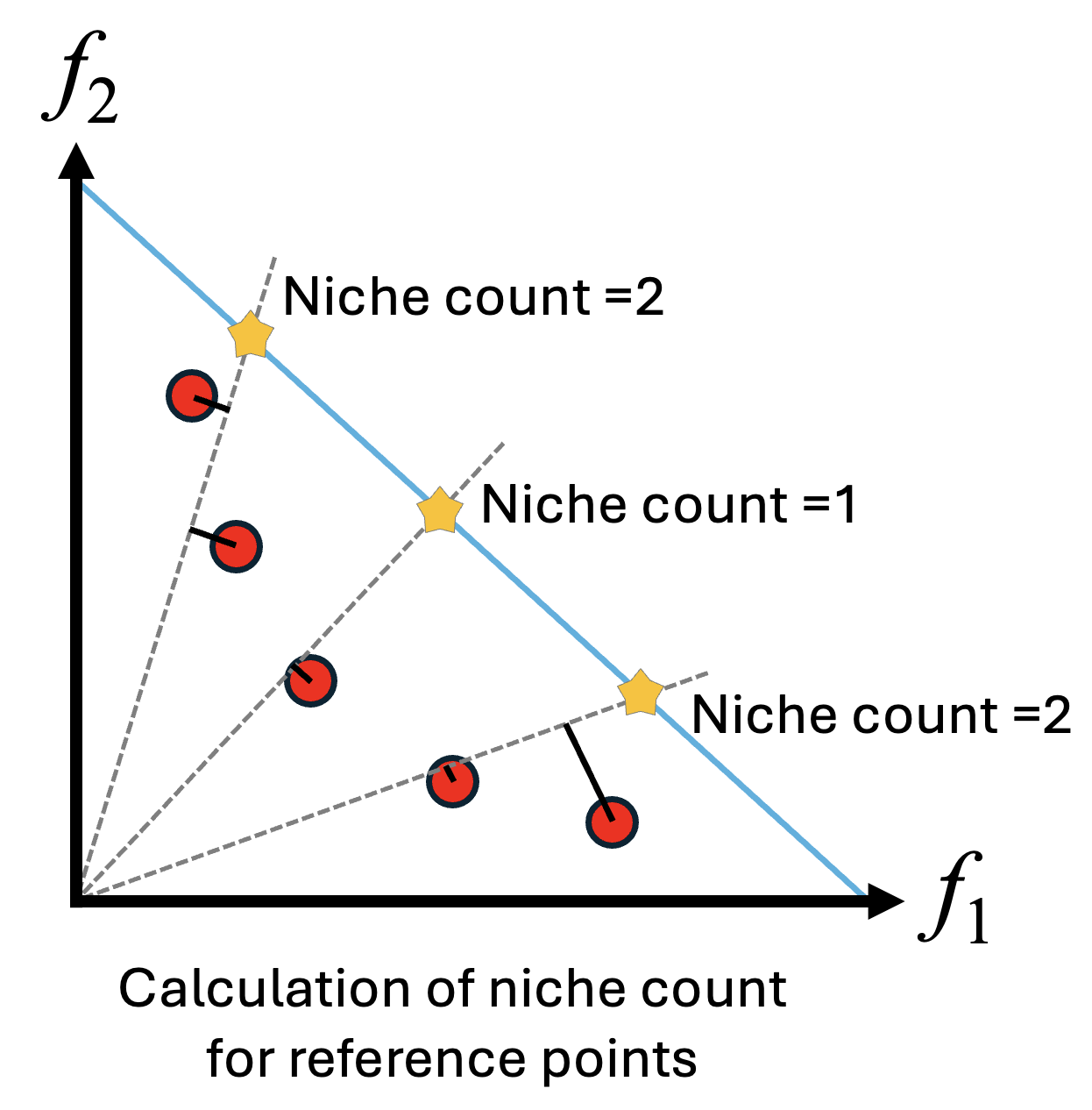
- 参照点との関連付け:目的空間上に均等に配置された複数の参照点を設定し、各個体から最も距離が近い参照点を見つけ、個体をその参照点に関連付けます。
- 参照点に間れ付けられた個体数をニッチ数といいます。
- 個体の選択:ランクが小さい個体を優先して選択しますが、同一ランク内で優劣を決める際には、NSGA-II の混雑距離の代わりに参照点を用います。
- ニッチ数が少ない参照点を優先し、その参照点に最も近い個体を、次世代に残す個体として選択します。
| Step 1 | Step 2 |
|---|---|
 |
 |
MOEA/D(分解ベース型)
Multiobjective Evolutionary Algorithm based on Decomposition [5]
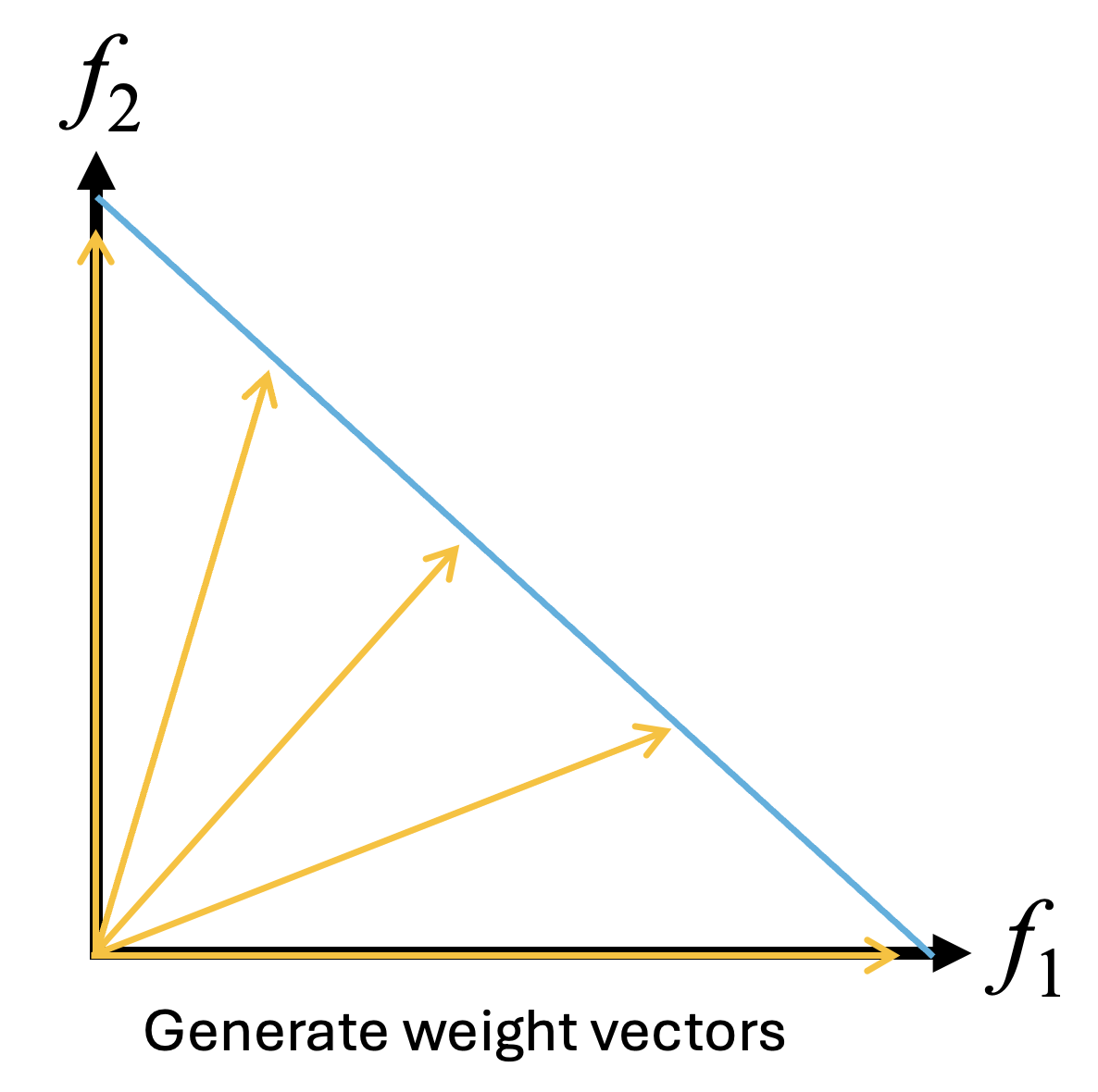
- 問題の分解:元の多目的最適化問題を、あらかじめ設定した複数の重みベクトルとスカラー化関数を用いて、複数の単一目的最適化問題(サブ問題)に分解します。
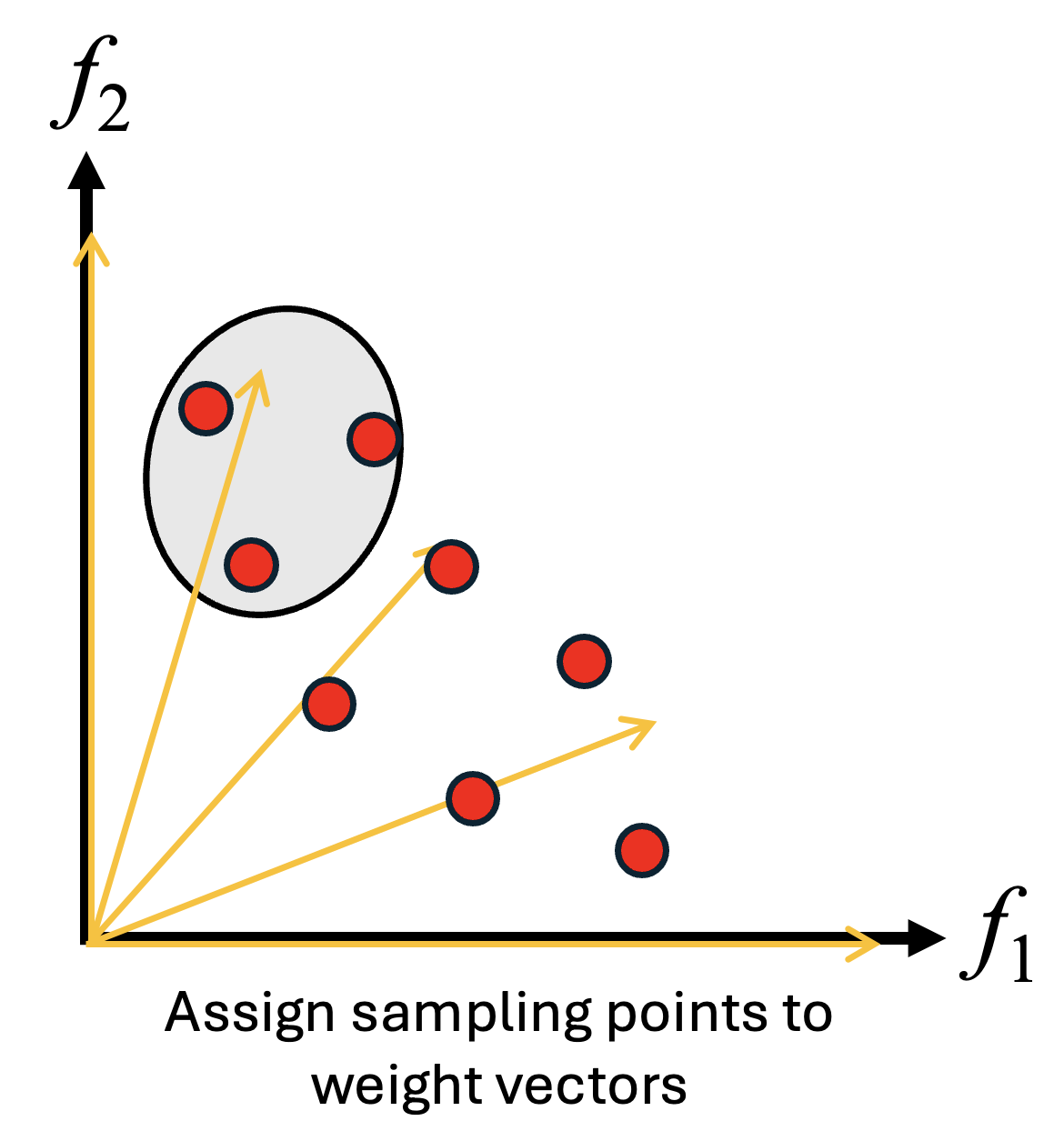
- 近傍の定義と進化:各サブ問題に割り当てられた重みベクトルの距離が近いものを「近傍」として定義します。個体の交叉や突然変異といった進化操作は、集団全体からランダムに選ぶのではなく、この近傍内の個体同士で行われます。
- 解の更新(個体の選択):新しく生成された個体が、近傍内にあるサブ問題の現在の解よりも目的関数の値(スカラー値)を改善できる場合、その個体で置き換えます。
- 各サブ問題の最適解を局所的に探索し続けることで、結果的にパレートフロント全体を近似する個体群が維持されます。
| Step 1 | Step 2 |
|---|---|
 |
 |
各手法の比較
紹介した各手法の比較を行います。
比較は最適化ライブラリOptunaで利用可能な以下の実装で行います。これらはOptuna公式の実装を元に、筆者が実装しOptunaHubで公開しているものになります。
- NSGA-II:https://hub.optuna.org/samplers/nsgaii_with_initial_trials/
- NSGA-III:公式の実装に突然変異の処理を追加
- MOEA/D:https://hub.optuna.org/samplers/moead/
- SPEA-II:https://hub.optuna.org/samplers/speaii/
- HypE:https://hub.optuna.org/samplers/hype/
これらの実装を用いて、以下では3つの観点から各手法を比較します。本記事では評価したい観点に応じて DTLZ2、DTLZ4、DTLZ7 [6]を使い分けています。
まず比較1では、3目的の DTLZ2 を用いて、各手法が生成するパレートフロントの分布形状を確認します。ここでは、解がどれだけ均一に広がるかという多様性と、フロント全体をどの程度広くカバーできるかという被覆性に着目し、各手法の分布の作り方の違いを見ます。
次に比較2では、DTLZ4 と DTLZ7 を対象に目的関数の数を 2 から 10 まで変化させ、IGD+ を用いて目的数の増加に対する性能変化を評価します。連続かつ滑らかなフロントを持つ DTLZ4 と、不連続かつ局所的な構造を持つ DTLZ7 を併せて用いることで、各手法のスケーリング特性と問題構造への適応性の両方を確認します。
比較3では、比較2と同様の設定のもとで計算時間を比較し、解の品質だけでなく実行コストも含めた実用上のトレードオフを整理します。
この比較により「解の分布」「目的数の増加」「計算コスト」という3つの観点から、進化型多目的最適化の特徴を立体的に捉えることを目指します。
比較1:3目的でのパレートフロント形状
比較条件
- 最適化手法:NSGA-II、SPEA-II、NSGA-III、HypE
- 交叉手法:SBX、分布指標 η=20
- 突然変異手法:Polynomial、分布指標 η = 20
- 目的関数の数:3
- 目的関数:DTLZ2
- 変数の数:15
- 試行回数:50個体 x 50世代(合計2500個体)
DTLZ2は以下のような0~1の範囲の球状のパレートフロント面が最適解になります。
| 45度視 | 側面視 |
|---|---|
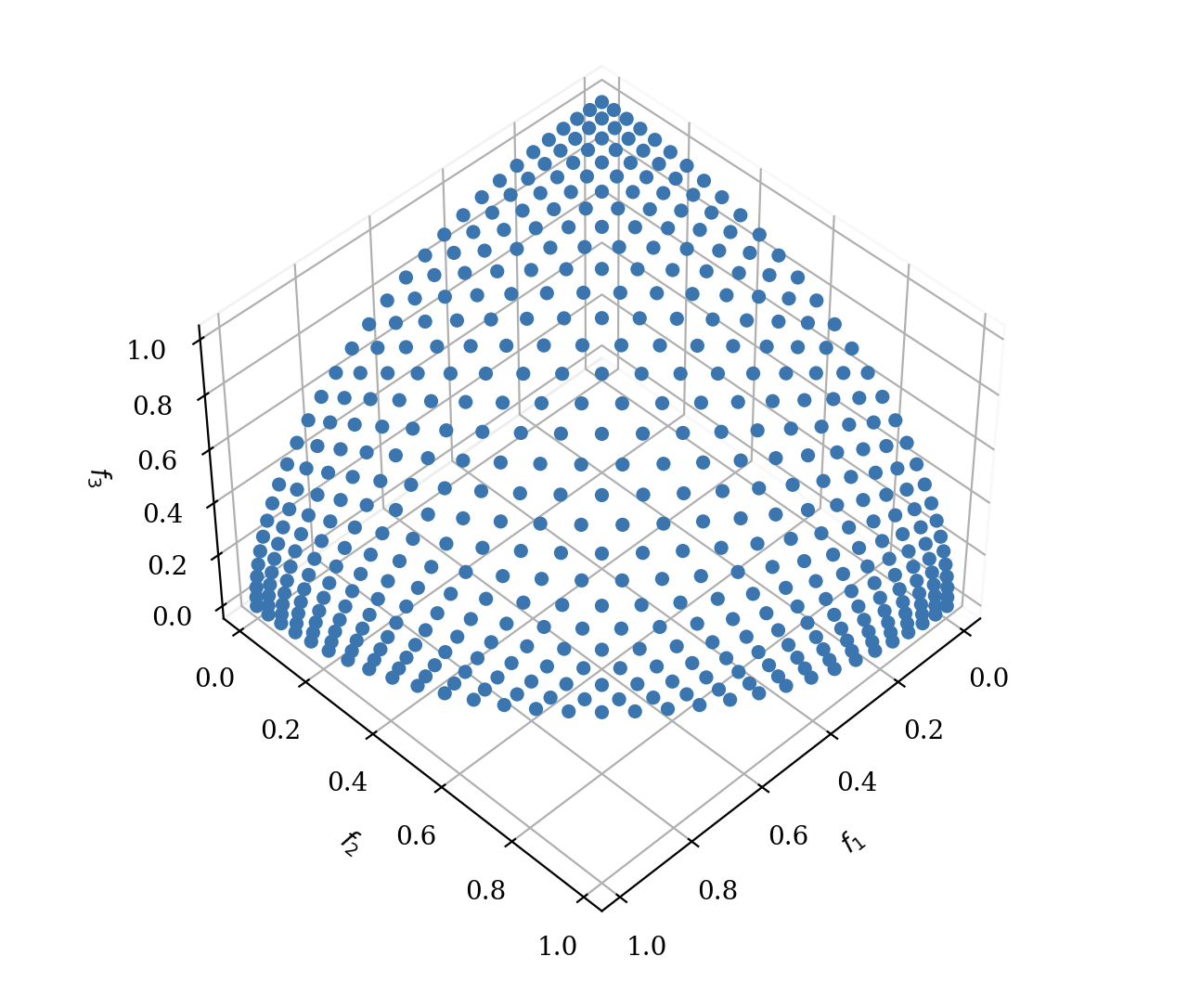 |
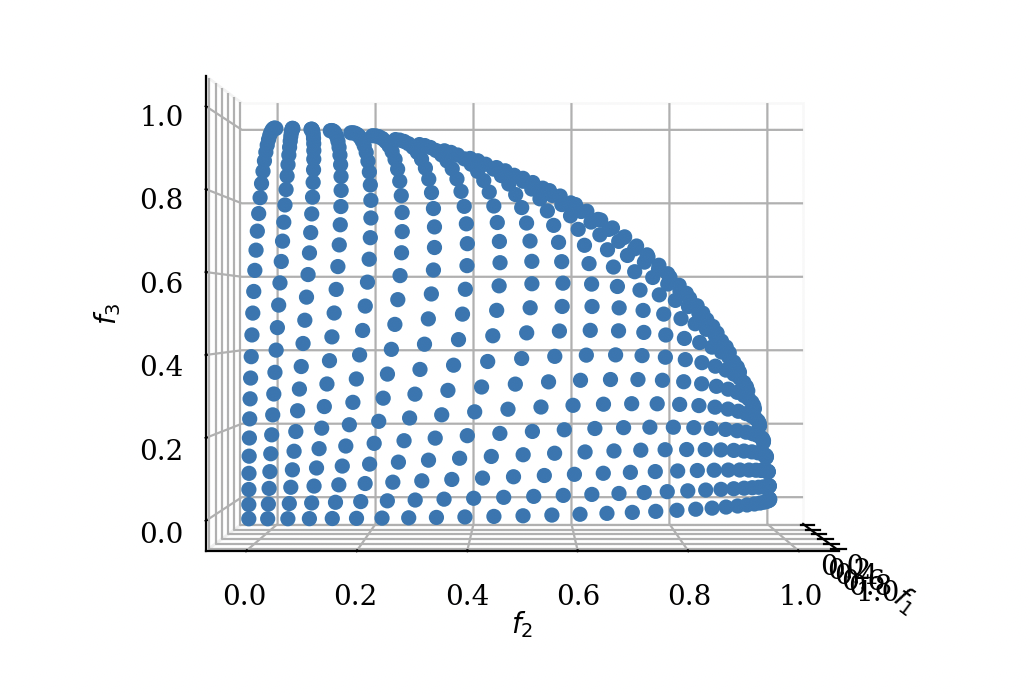 |
本比較では、各手法によって得られるパレートフロントの形状について、以下の2つの観点から評価を行います。
- 多様性:フロント上における解の分布がどれだけ均一であるか
- 被覆性:フロント全体をどの程度広くカバーできているか
目的関数は3目的ですが、目的関数の1と2のみを表示する2次元のパレートフロント図を本比較では確認します。グラフ中の黒点線は、これより内側に存在する曲面が真のパレートフロントであることを表しています。
最終世代の分布の確認
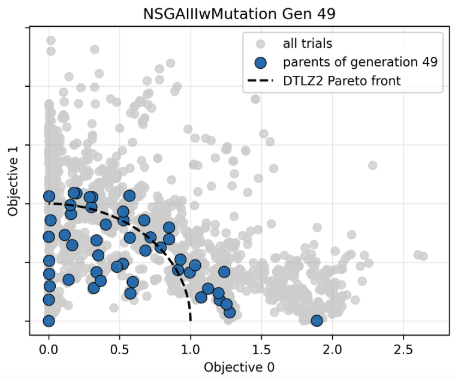
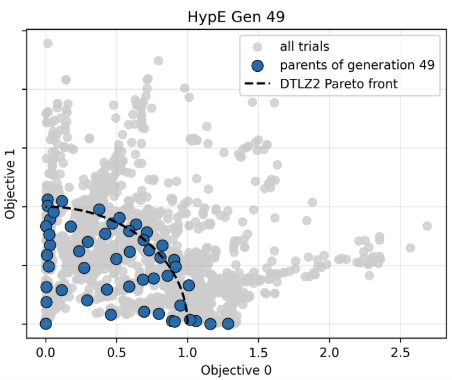
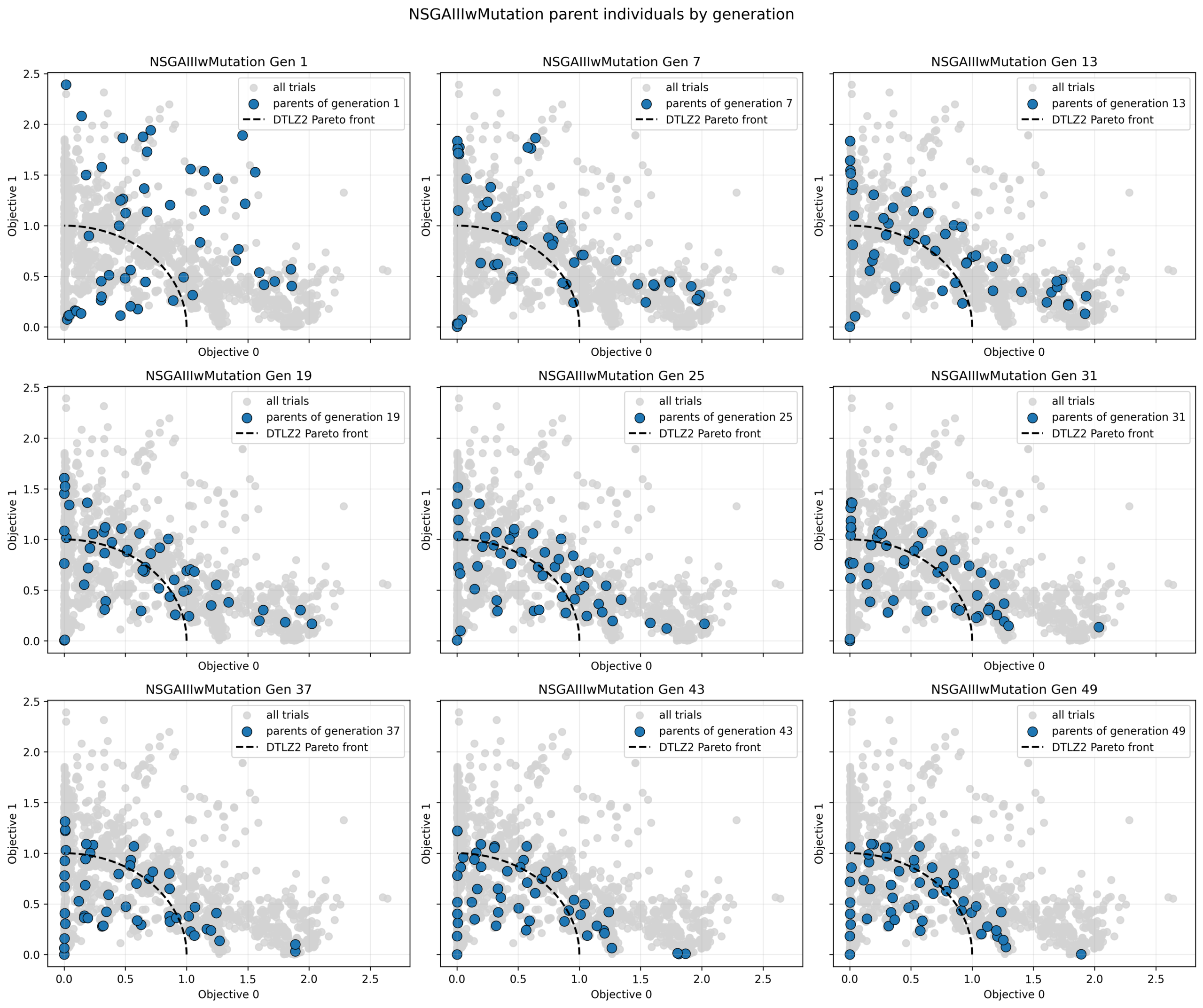
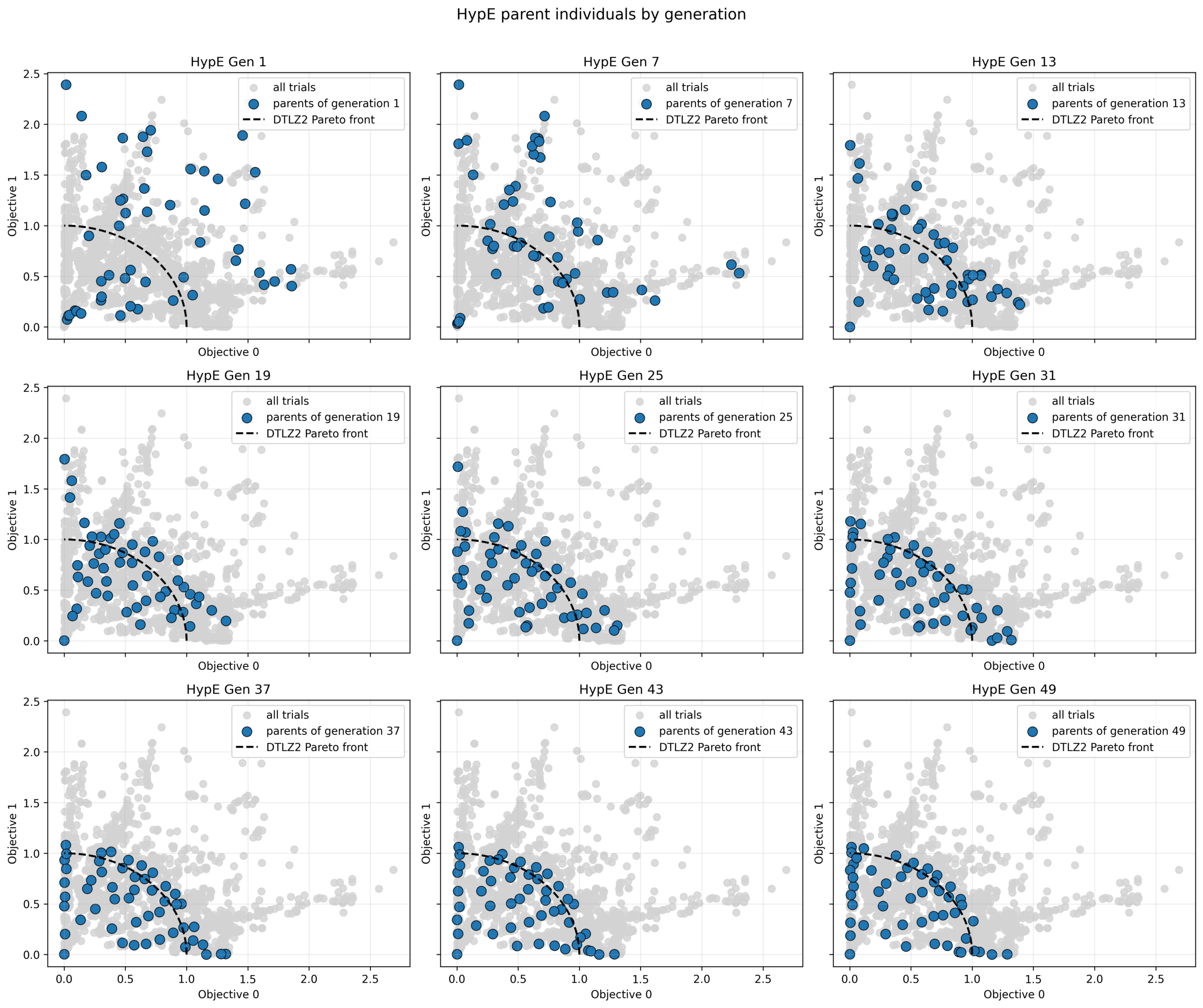
各最適化手法ごとに最終世代の個体分布を以下に示します。NSGA-IIIやHypEの結果は最終世代の個体を表す水色の点の多くが黒点線の内側に多くあります。
今回の条件では、NSGA-III や HypE のほうが、NSGA-II や SPEA-II よりも、最終世代でより均一で被覆性の高い個体分布を示す傾向が見られます。
| NSGA-II | SPEA-II |
|---|---|
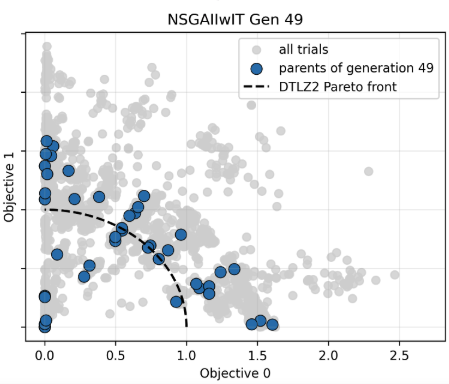 |
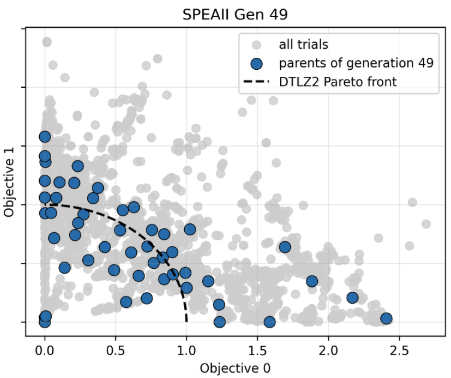 |
| NSGA-III | HypE |
|---|---|
 |
 |
各手法における最終世代の分布を詳細に見ると、次のような傾向が確認できます。
- NSGA-II
パレートフロント近傍への収束は確認できるものの、解が中央付近に集中しやすく、フロントの端点付近のカバーが弱い傾向があります。これは混雑距離に基づく選択が局所的な密度に依存するため、高次元では分布の均一性を維持しにくいためだと考えられます。 - SPEA-II
NSGA-IIと同様に収束はしていますが、全体的にばらつきが大きく、ノイズのような分布が残りやすいです。\(k\)近傍に基づく密度評価は局所構造に敏感であり、均一な分布を形成しにくい傾向があります。 - NSGA-III
フロント全体にわたって比較的均一な分布が得られています。これは参照点に基づいて解の配置が誘導されるためであり、探索空間全体をバランスよくカバーする性質によると考えられます。 - HypE
フロントの端点付近の解が比較的強く維持されています。ハイパーボリューム最大化の特性上、他の解ではカバーしにくい領域(特に端部)の解が高く評価されるためです。一方で中央付近の密度はやや不均一になる場合があります。
世代ごとの結果推移
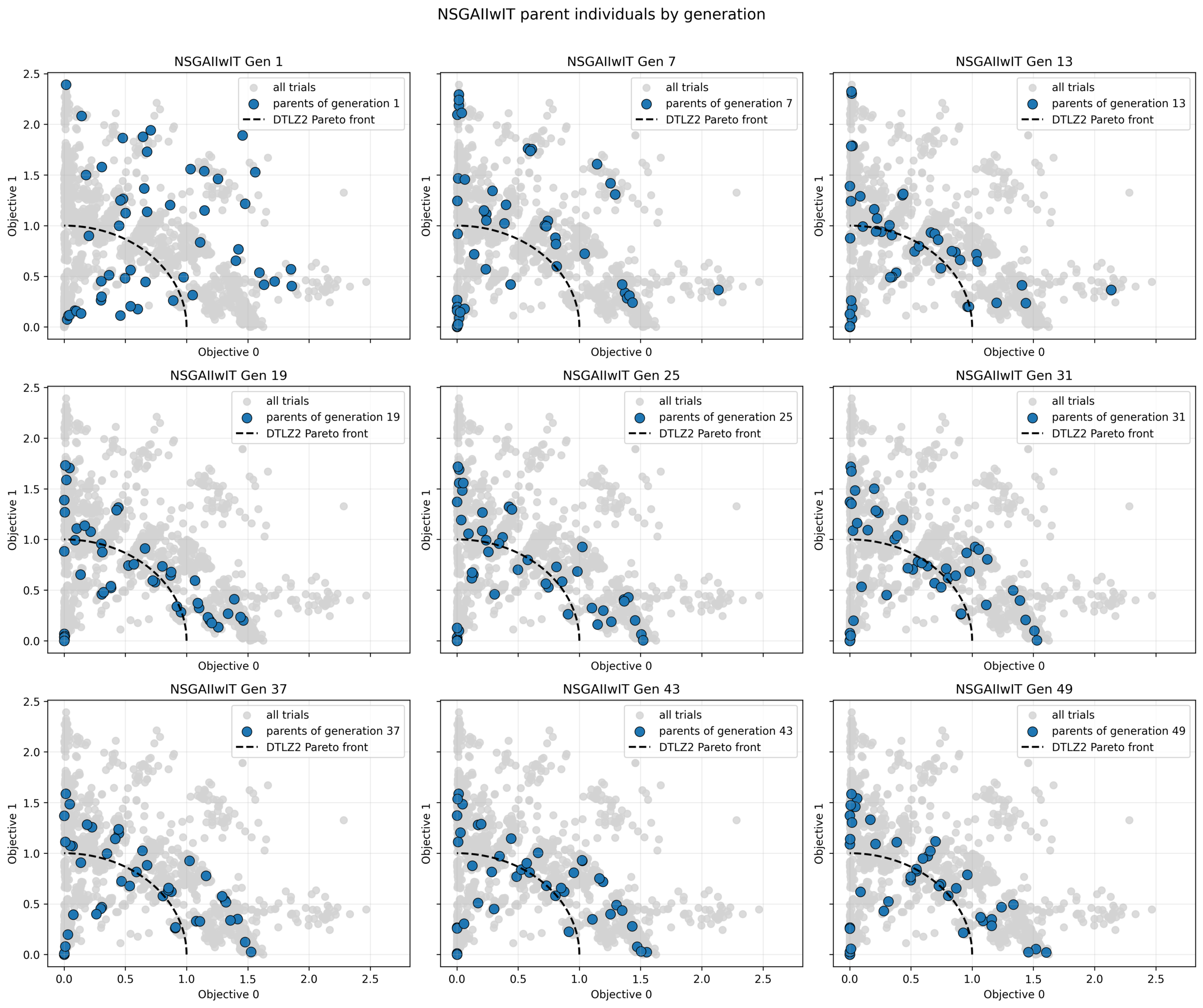
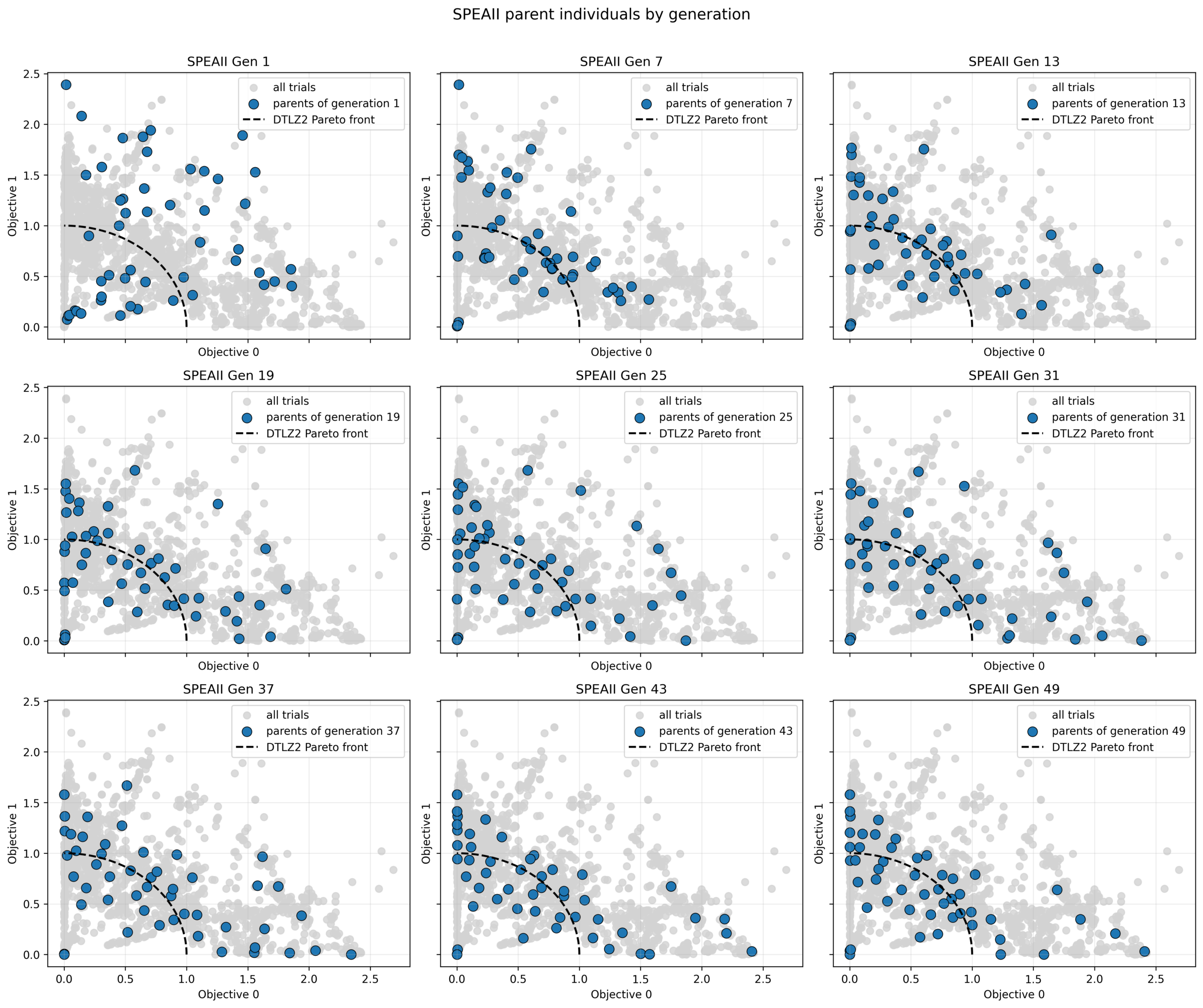
次に世代の進行に伴う個体の分布の変化を確認します。
初期世代では同じシードを用いているためどの手法も同じランダムな分布を示していますが、世代が進むにつれて徐々にパレートフロント近傍へと収束していくことがわかります。中盤以降になると、各手法の多様性の扱いの違いが現れ、最終的な分布の形状に差が出ています。
NSGA-II
SPEA-II
NSGA-III
HypE
まとめ
本比較の範囲では、3目的問題におけるパレートフロントの形状という観点では、NSGA-IIIおよびHypEが、分布の均一性および被覆性の面で比較的良好な結果を示しました。
一方で、NSGA-IIおよびSPEA-IIもパレートフロントへの収束自体は可能ですが、解の分布に偏りが生じやすく、特にフロントの端部の探索が不十分になる傾向がみてとれます。
多くの目的関数が存在する問題や、解の分布の均一性が重要となる問題においては、参照点ベースや指標ベースの手法が有効だと考えられます。
比較2:目的関数の数でのパフォーマンス
比較条件
-
最適化手法:NSGA-II、SPEA-II、NSGA-III、HypE、MOEA/D
- NSGA-IIIでは参照点数が100個程度になるように目的関数の数に合わせて分割数を設定
- 2目的:99、3目的:12、5目的:4、8目的:3、10目的:2
- MOEA/Dは分解関数はTchebycheff、近傍サイズは10として設定
- NSGA-IIIでは参照点数が100個程度になるように目的関数の数に合わせて分割数を設定
-
交叉手法:SBX、分布指標 η=20
-
突然変異手法:Polynomial、分布指標 η = 20
-
目的関数:DTLZ4、DTLZ7
-
目的関数の数:2, 3, 5, 8, 10
-
変数の数:目的関数で推奨の以下の変数の数を使用
目的関数の数 DTLZ4の変数の数 DTLZ7の変数の数 2 11 21 3 12 22 5 14 24 8 17 27 10 19 29 -
試行回数:100個体 x 100世代(合計10000個体)、シード値を変化させ20回行う
-
評価方法:IGD+指標
- 理想のパレートフロント上の各点に対して、現在得られている解集合の中で最も近い点までの距離を計算し、その平均を取った指標です。
- IGD+では劣方向(支配される方向)の距離のみを考慮することで、単純な距離を計算するIGDよりも適切に解の質を評価できるようになっています。
- 値が小さいほど理想のパレートフロントに近いことを示します。
| DTLZ4 パレートフロント | DTLZ7 パレートフロント |
|---|---|
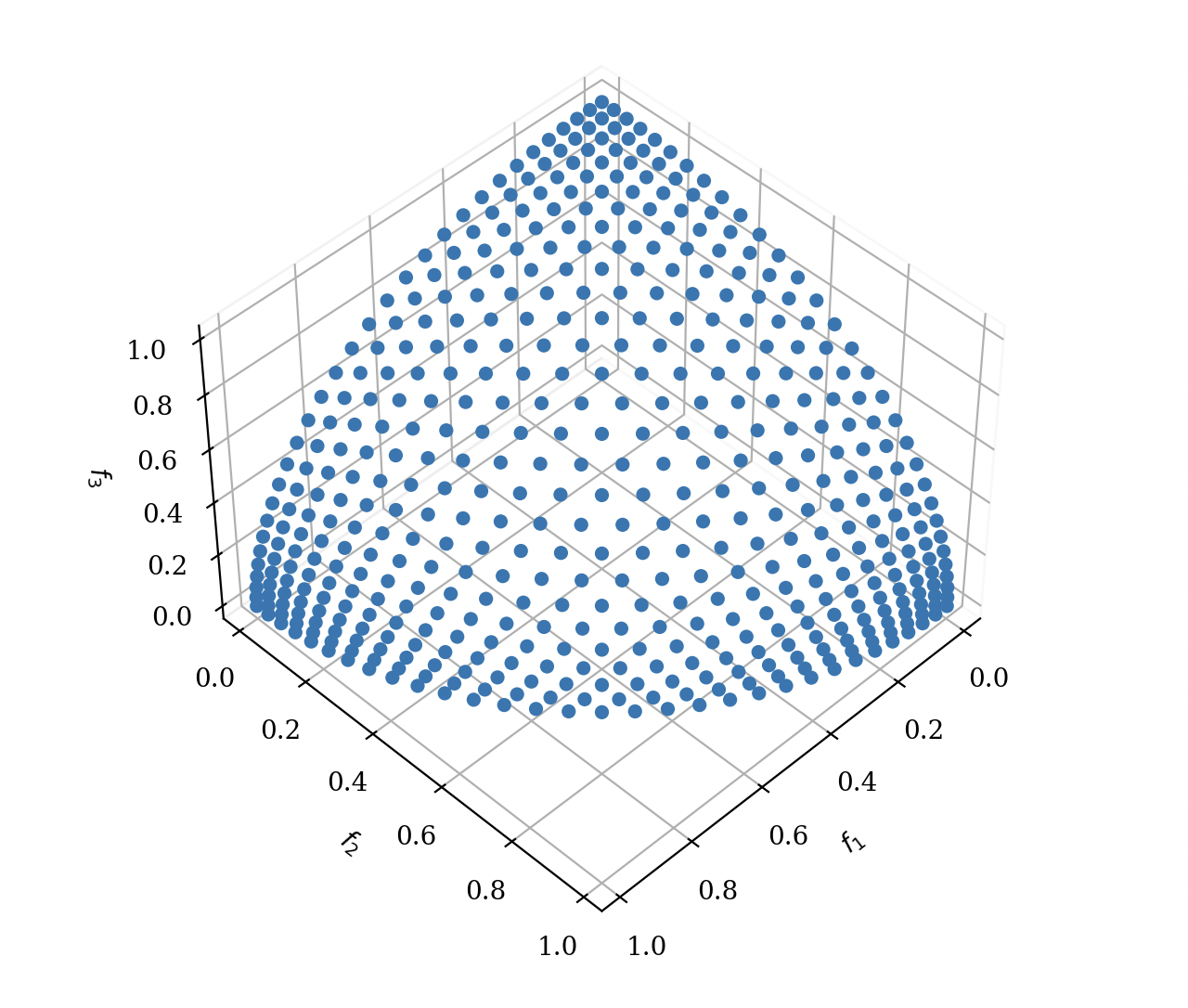 |
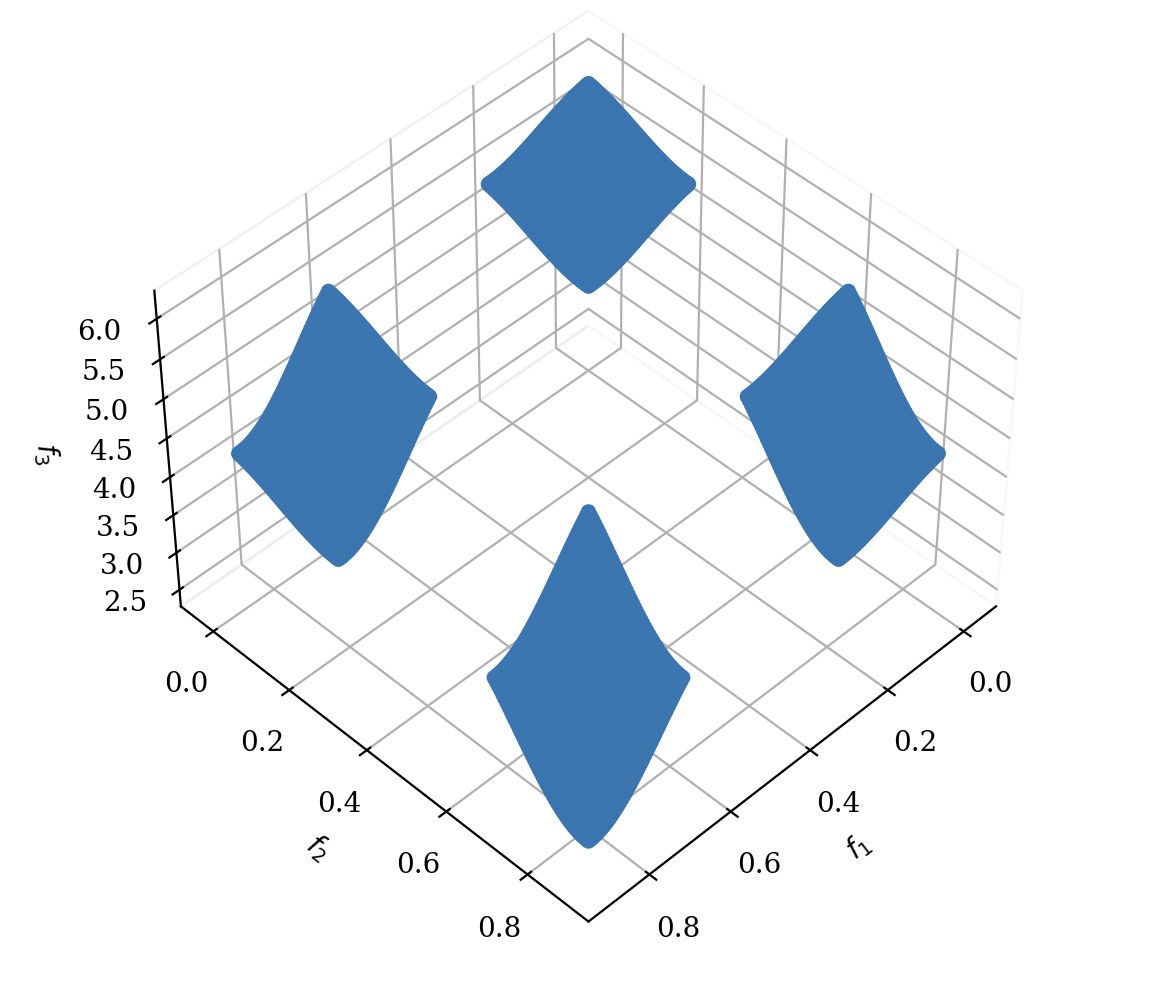 |
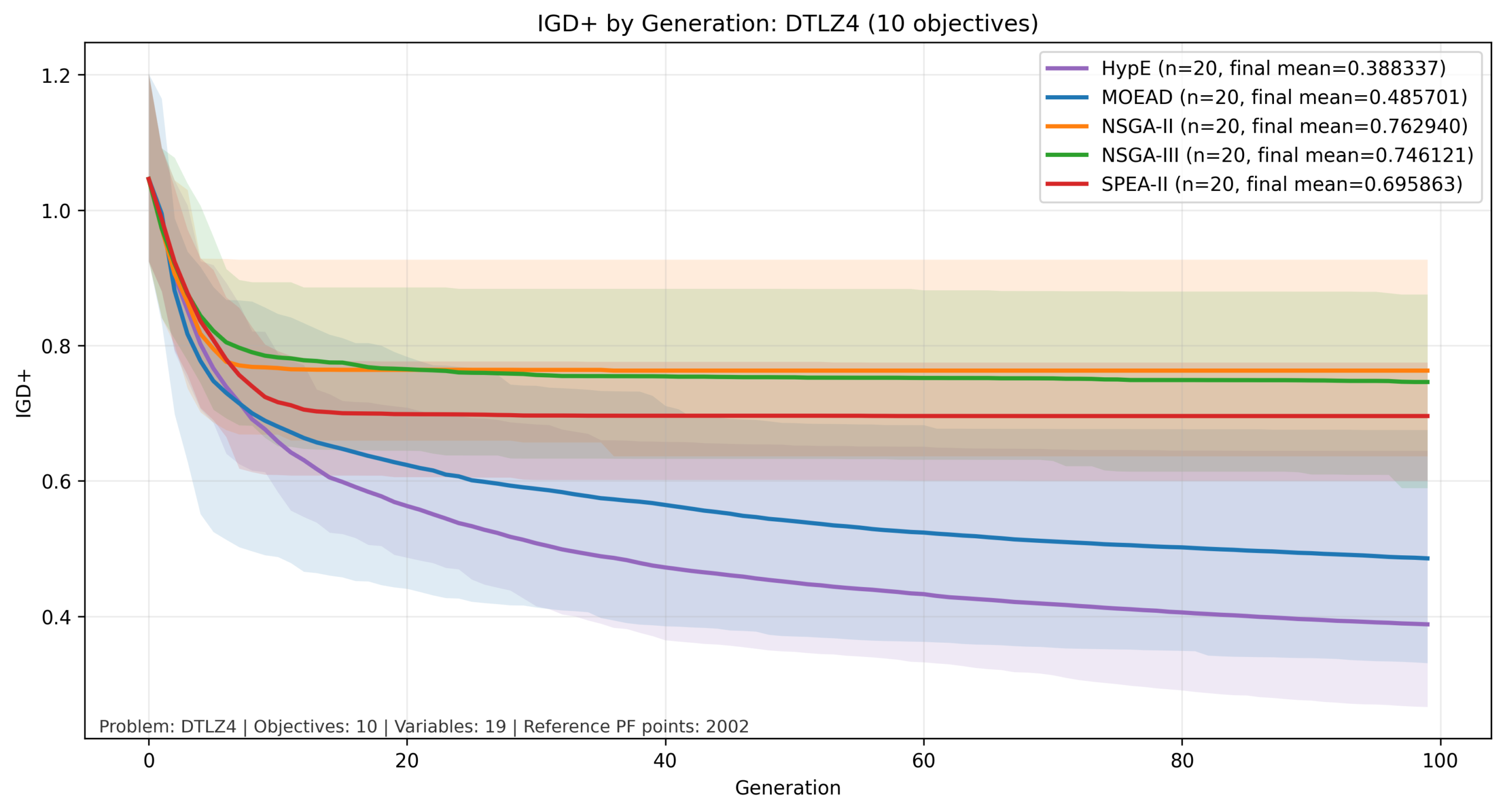
比較結果:DTLZ4
縦軸を対数でIGD+の計算結果、横軸を世代数とした図を以下に示します。実線が平均値、色付きの範囲が最大値と最小値の範囲になります。
今回の比較では、3目的まではNSGA-IIとNSGA-IIIが他と比べて良い結果となっていますが、目的数が増加すると MOEA/D と HypE が比較的良好な結果を示しています。この傾向は、目的関数の数が増加した際の各手法のスケーリング特性の違いによるものと考えられます。
NSGA-II はパレート支配に基づく選択を行うため、目的数が増加すると個体間の優劣がつきにくくなり、探索の選択圧が弱まる傾向があります。
一方でNSGA-IIIは参照点によって分布を誘導することでこの問題をある程度緩和できますが、高次元では参照点の密度が不足しやすくなります。
これに対して、MOEA/Dは問題を分解して個別に最適化するため目的数の増加に対して比較的安定しており、HypEはハイパーボリュームという単一指標を用いることで多目的環境においても適切な選択圧を維持できるため、後半の世代まで改善が継続したと考えられます。
| 2目的 | 3目的 |
|---|---|
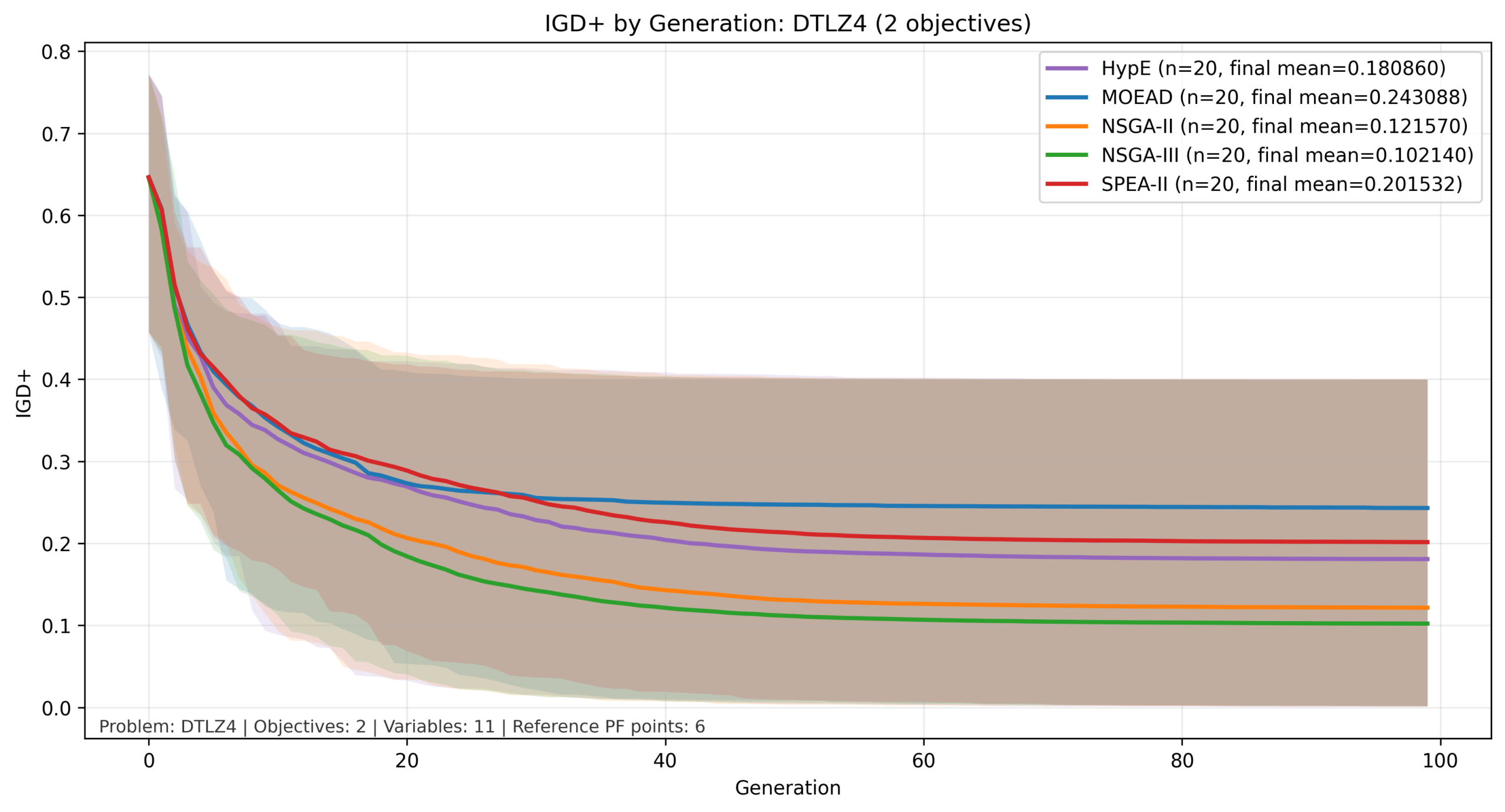 |
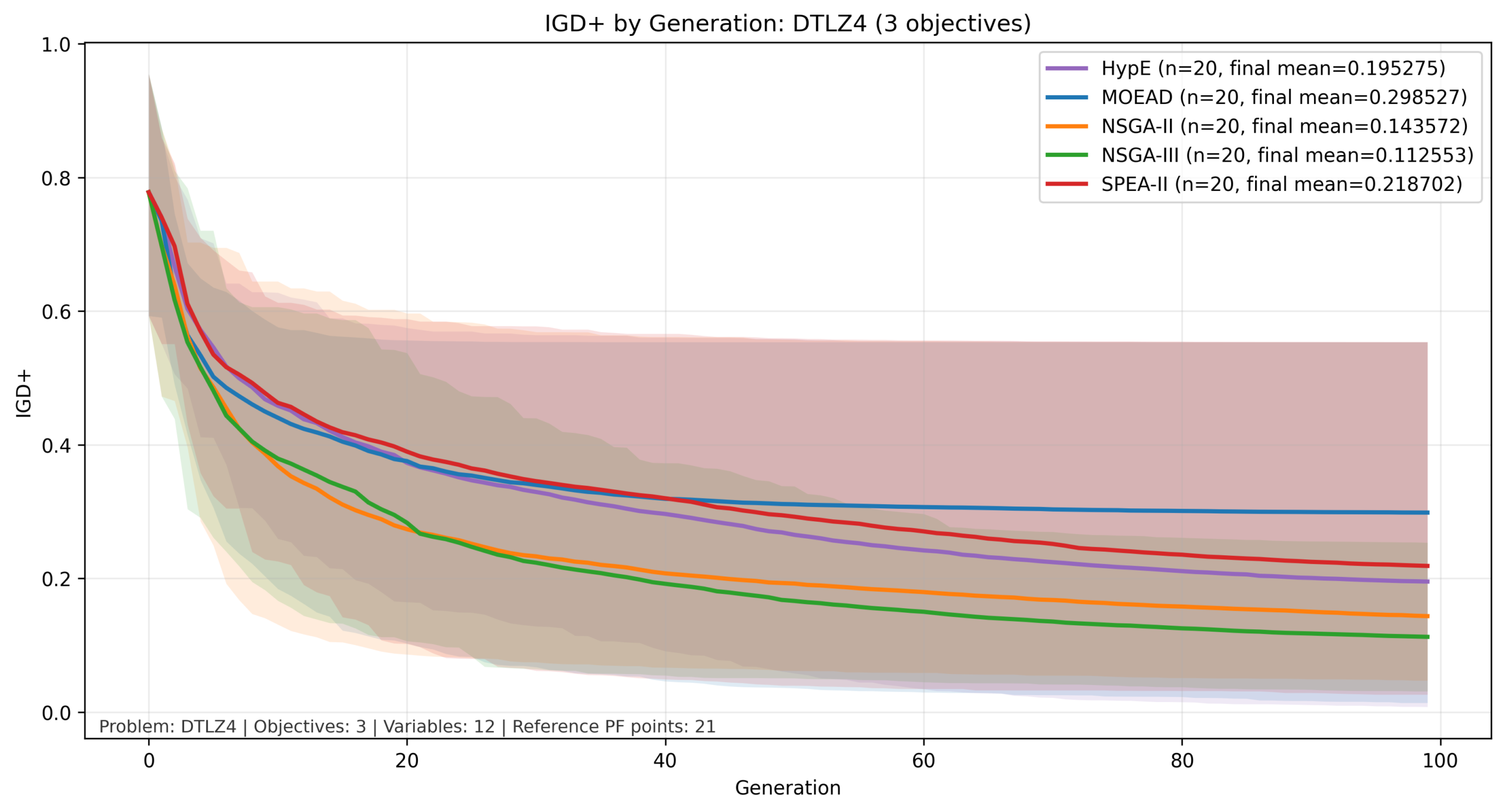 |
| 5目的 | 8目的 |
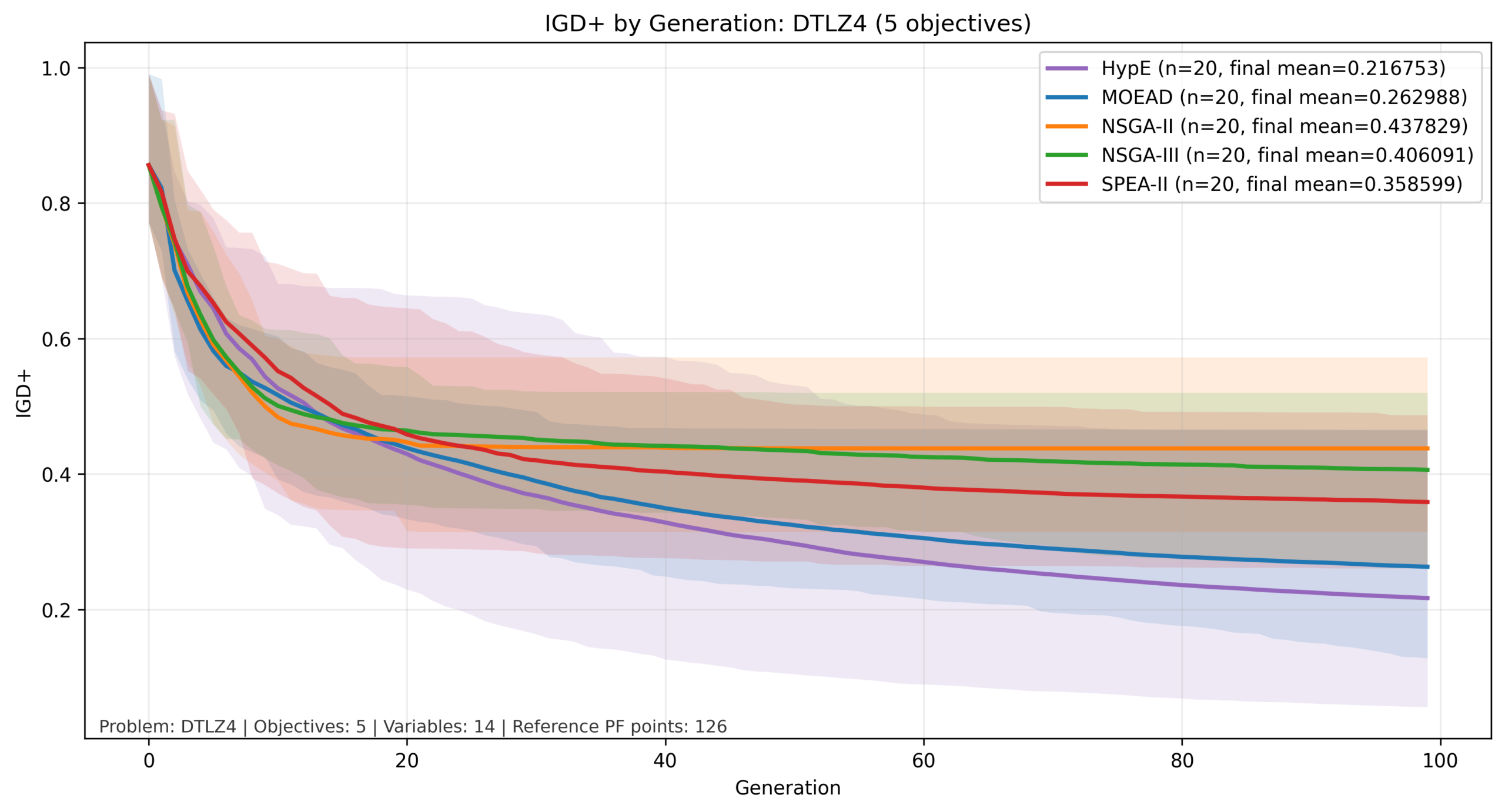 |
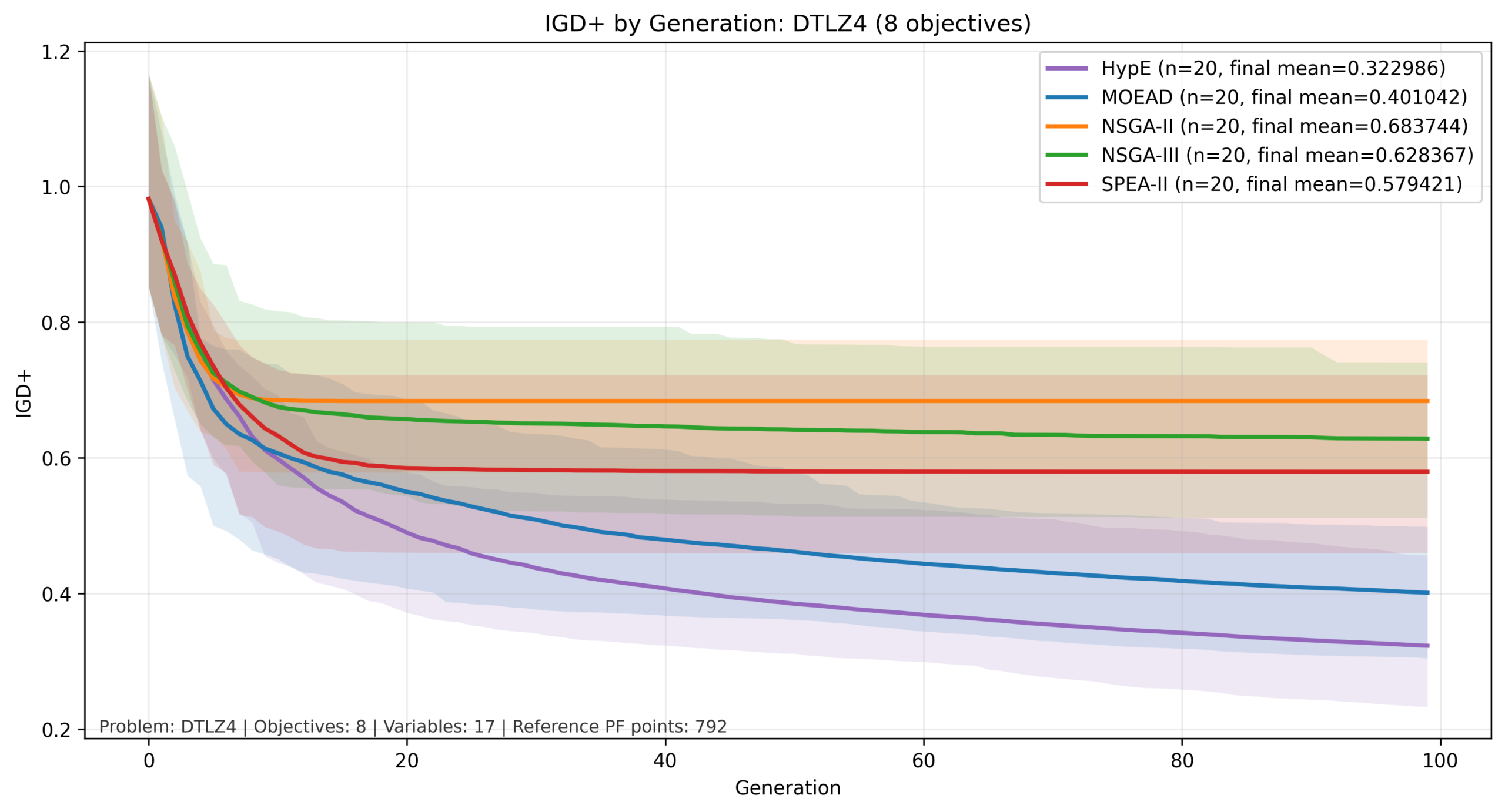 |
| 10目的 | |
 |
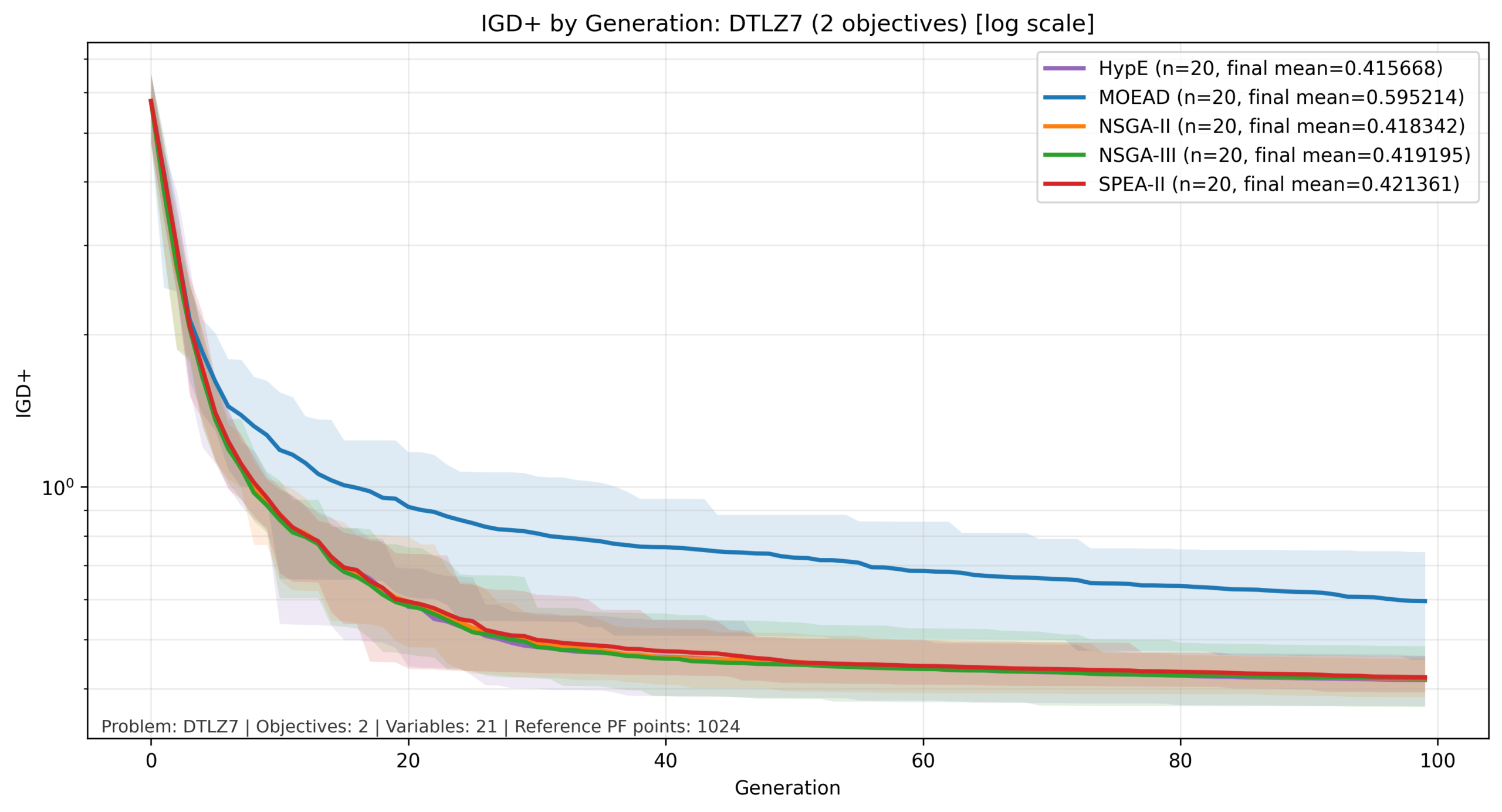
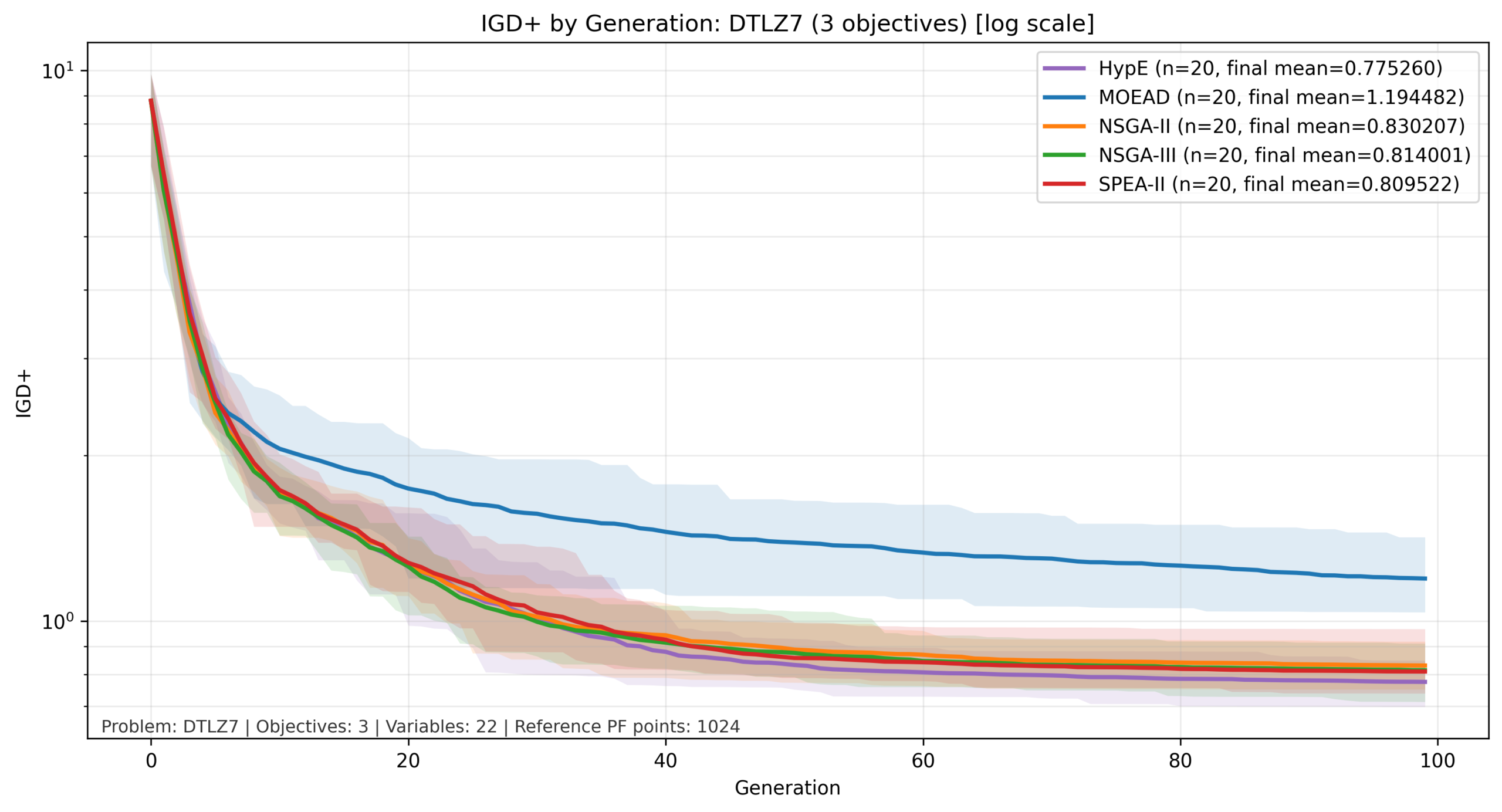
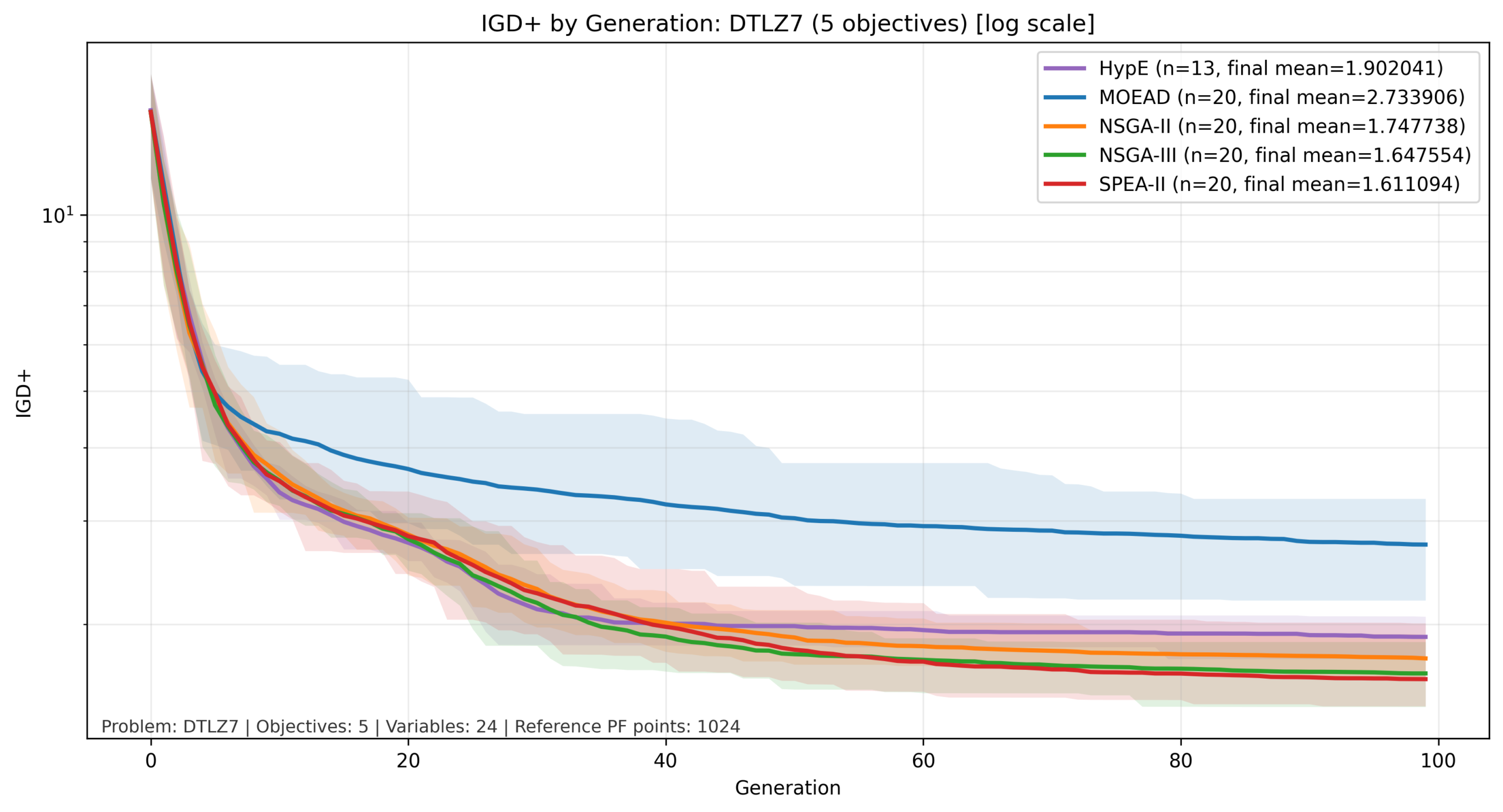
比較結果:DTLZ7
DTLZ7では、IGD+値の変化幅が大きいため、縦軸は対数軸としています。
DTLZ7では、他の問題とは異なる傾向が確認されました。本結果では一貫して MOEA/D の成績が低く、一方で SPEA-II がすべての目的数で比較的良好な性能を示しています。
この要因として、DTLZ7 のパレートフロントが不連続かつ局所的に分布する構造を持つことが考えられます。今回の設定では、MOEA/D は Tchebycheff 分解と固定した近傍構造 に基づいて探索しているため、このような非連続なフロントに対しては探索のしやすさが低下した可能性があります。
一方で、本結果は 「MOEA/D が DTLZ7 に一般に不向きである」ことを直接示すものではなく、少なくとも今回の分解関数・近傍設定では不利な挙動が見られたと解釈することができます。
SPEA-II は、パレート支配と局所的な密度評価を組み合わせて個体を選択するため、このような非一様なフロントに対しても比較的安定した性能を示したと考えられます。
| 2目的 | 3目的 |
|---|---|
 |
 |
| 5目的 | 8目的 |
 |
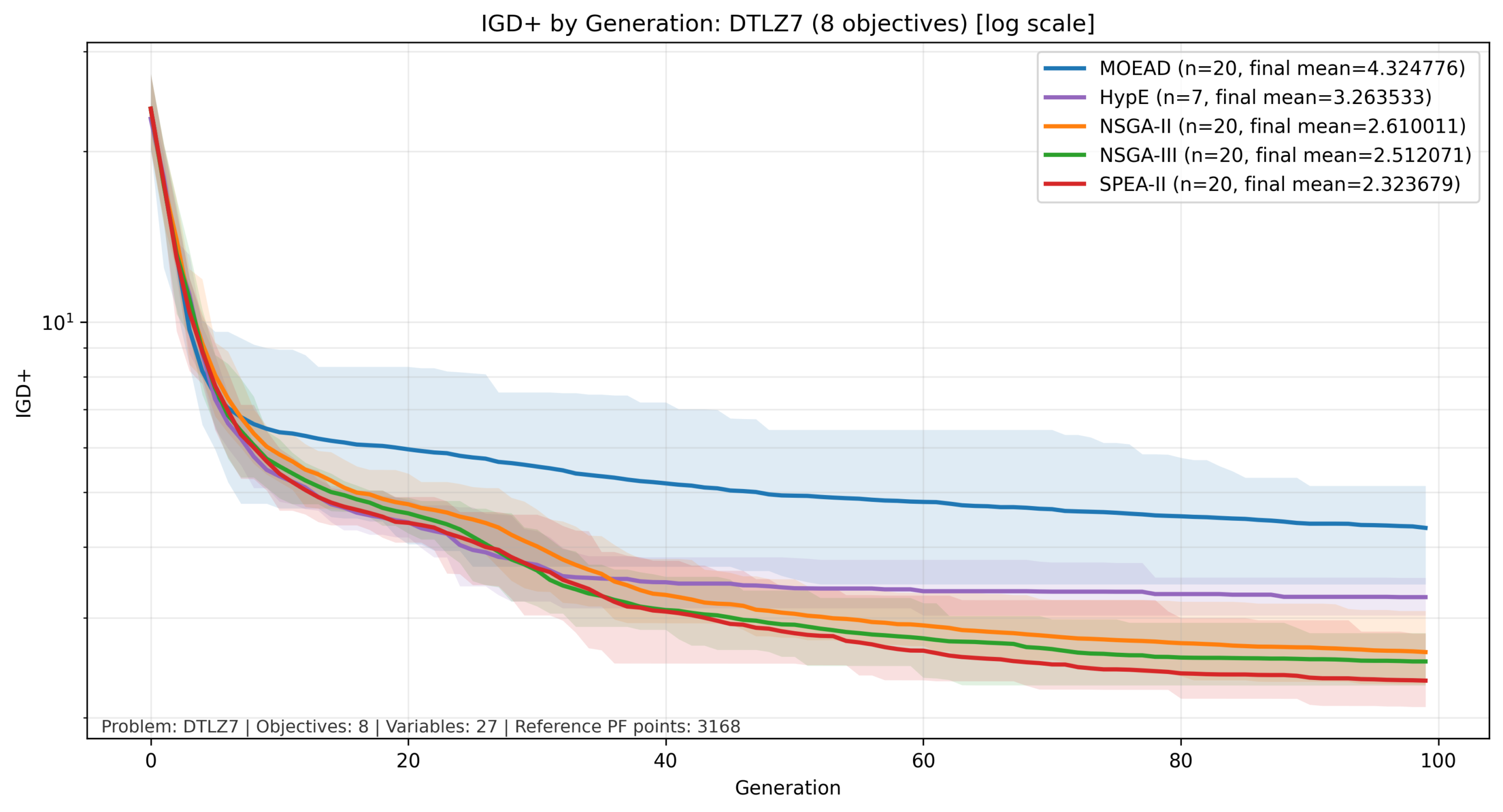 |
| 10目的 | |
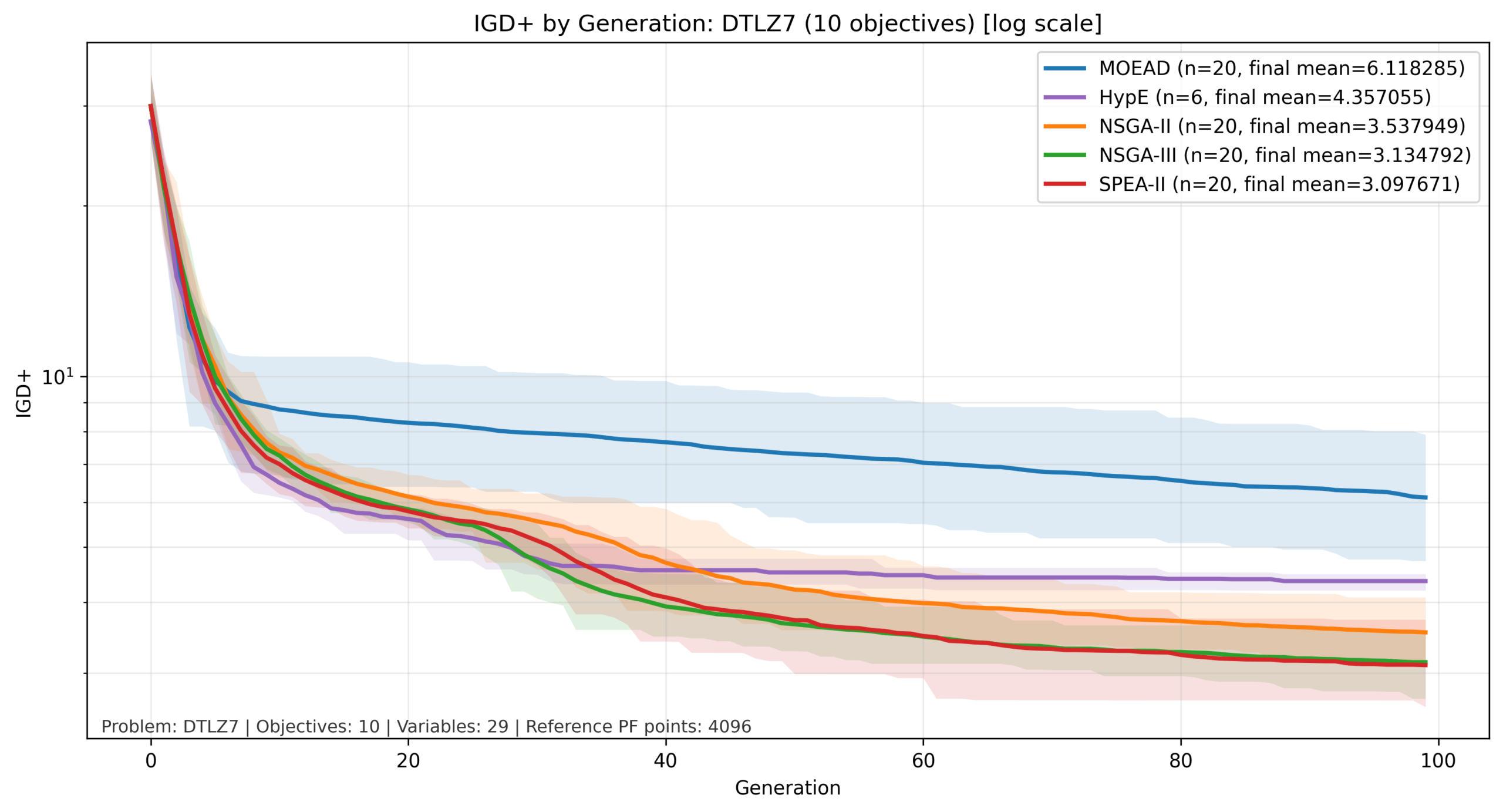 |
まとめ
以上の結果から、目的関数の数および問題構造によって適した手法が大きく異なることが確認できました。
まず DTLZ4 のようにパレートフロントが連続かつ滑らかな問題では、目的数が少ない場合は NSGA-II や NSGA-III が有効ですが、目的数が増加すると MOEA/D や HypE のような分解ベース・指標ベース手法が優れた性能を示します。これは、多目的化に伴う支配関係の弱体化に対して、これらの手法が安定した選択圧を維持できるためです。
今回の比較では、DTLZ7 のような不連続で局所的な構造を持つ問題において、MOEA/D は不利な傾向を示し、SPEA-II は比較的安定した性能を示しました。
これらの結果から、多目的最適化においては単に目的数だけでなく、パレートフロントの形状(連続性・均一性・局所構造)を考慮して手法を選択することが重要であるといえます。
比較3:計算時間
比較条件
本比較における計算時間は、以下の条件で計測しています。
- 個体数および世代数:比較2と同一(100個体 × 100世代)
- 目的関数:DTLZ4, DTLZ7
- 実行環境:単一スレッドで実行
- 試行回数:シード固定で1回のみ
なお、本比較は各手法の計算時間の傾向を把握することを目的としており、統計的な平均値ではなく単一試行の結果である点に注意してください。
- NSGA-II / NSGA-III:非支配ソートや参照点処理に起因して、個体数が増えると二乗オーダーで重くなりやすい
- SPEA-II:密度推定やアーカイブの刈り込み処理がボトルネックになりやすく、条件によっては高コストになりうる
- MOEA/D:各世代の更新自体は比較的軽量だが、重みベクトルや近傍構造の構築など、初期化や実装依存のオーバーヘッドの影響を受ける
- HypE:ハイパーボリューム推定にサンプリングを用いるため、標本数を増やすほど計算時間は増加する。精度と計算時間のトレードオフを調整できる一方、高目的では依然として計算コストが大きくなりやすい
特に HypE は、ハイパーボリュームの推定に使用する標本数の設定によって性能と計算時間が大きく変わるため、実務では精度要件に応じた調整が必要です。今回は標本数を 4096 としています。
比較結果
各手法ごとの計算時間を次に示します。
はじめに、実行時間は乱数シードや初期個体の分布に影響を受けるため、本来は複数回試行の平均や分散で評価することが望ましいです。ですが、条件に記載したように本結果はあくまで1度だけ最適化を行ったものを代表とした挙動であり、特に計算コストの大きい手法(HypEなど)ではばらつきが生じる可能性があります。
結果を確認すると、紫色のHypEが他に比べて圧倒的に時間がかかっています。10目的の場合に絞ると、 MOEA/D も HypE を除く他の手法よりも非常に時間がかかっています。
図の縦軸は対数スケールで表示しています。そのため、見た目の差以上に実際の計算時間には大きな開きがあります。特にHypEは他手法と比較して1桁以上遅いケースが確認できます。
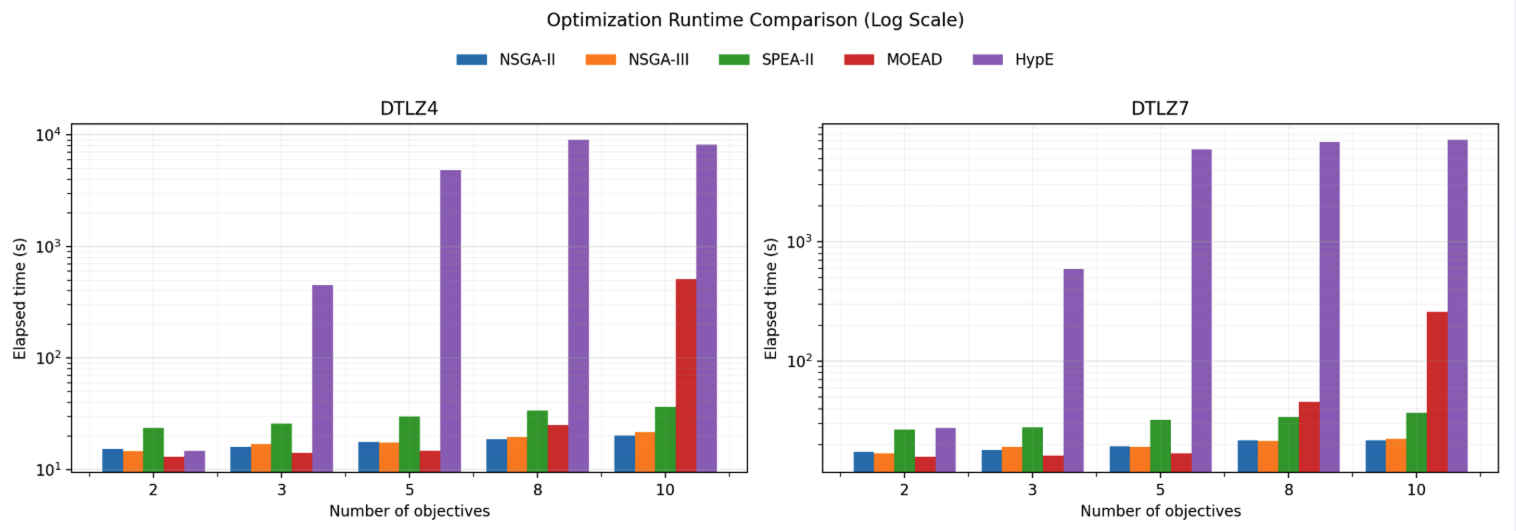
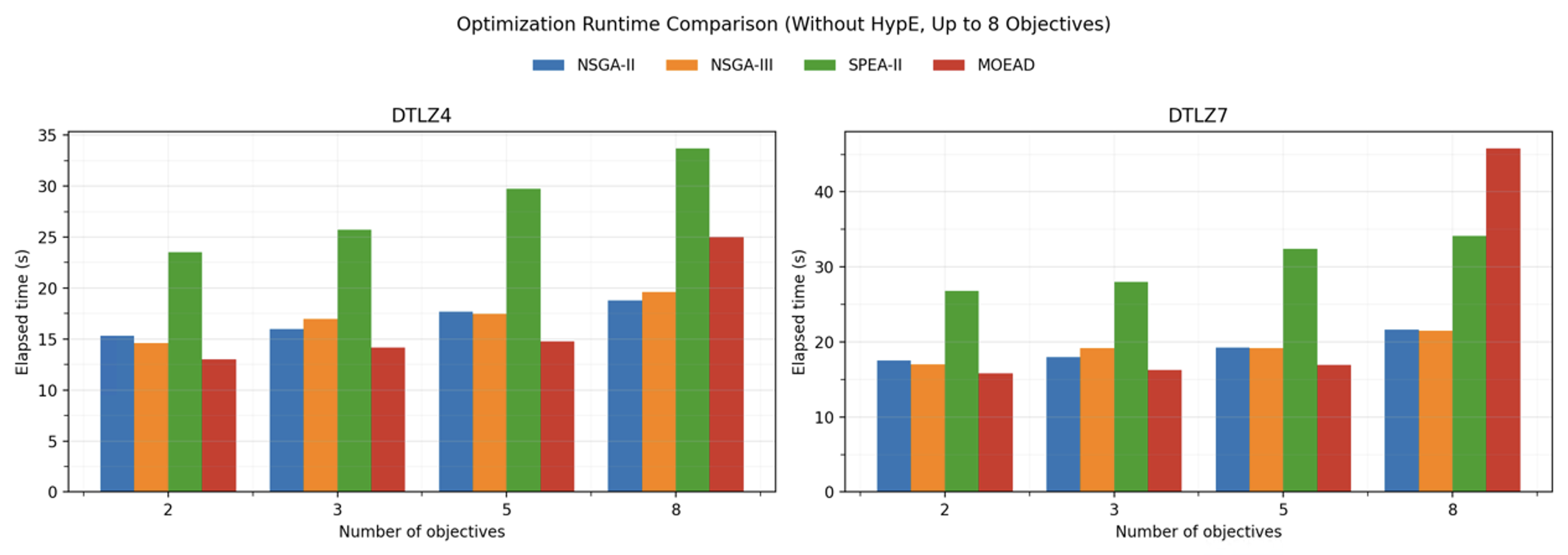
HypEと10目的の場合を除いた結果を確認すると以下のようになります。8目的でもMOEA/Dの計算時間が多くかかっていますが、それ以外では他の手法に対して高速に動作していることがわかります。
MOEA/D の計算時間が多くかかっている結果についてですが、サンプリングの時間の経過を確認すると、最適化問題を最初に部分問題に分解するステップで非常に時間がかかっていました。
理論上、MOEA/Dは軽量であり、世代更新自体は高速に動作することが期待されます。しかし今回の結果では、初期化時の分解処理や近傍構造の構築コストが支配的となっており、実装依存のオーバーヘッドが顕在化していると考えられます。
このため、MOEA/Dの計算時間は「世代あたりのコスト」だけでなく、「初期化コスト」を含めて評価する必要があります。
一方でそれ以外の場合はNSGA-IIに対して半分程度の時間で計算できており、各世代の更新が軽量であることの確認ができました。
参考に具体的な計算時間を以下に示します。
| DTLZ4 | 2objs | 3objs | 5objs | 8objs | 10objs |
|---|---|---|---|---|---|
| NSGA-II | 15.3 | 16.0 | 17.7 | 18.8 | 20.1 |
| NSGA-III | 14.6 | 17.0 | 17.5 | 19.6 | 21.6 |
| SPEA-II | 23.5 | 25.7 | 29.7 | 33.7 | 36.5 |
| MOEA/D | 13.0 | 14.2 | 14.8 | 25.0 | 510.3 |
| HypE | 14.7 | 449.7 | 4835.4 | 9066.1 | 8220.1 |
| DTLZ7 | 2objs | 3objs | 5objs | 8objs | 10objs |
|---|---|---|---|---|---|
| NSGA-II | 17.5 | 18.0 | 19.3 | 21.7 | 21.8 |
| NSGA-III | 17.0 | 19.2 | 19.2 | 21.5 | 22.4 |
| SPEA-II | 26.8 | 28.0 | 32.4 | 34.1 | 37.1 |
| MOEA/D | 15.8 | 16.3 | 17.0 | 45.8 | 260.9 |
| HypE | 27.5 | 594.8 | 5917.0 | 6898.1 | 7189.0 |
まとめ
計算時間の観点では、以下のような特徴が確認できました。
- MOEA/D:各世代の更新は比較的軽量だが、初期化コストや実装の影響を受けやすい
- NSGA-II / NSGA-III:安定した計算時間で、全体としてバランスのよい選択肢
- SPEA-II:密度推定やアーカイブ処理の影響で、条件によっては計算コストが大きくなりやすい
- HypE:高品質な解が期待できる一方で、サンプリング数と目的数に応じて計算時間が大きくなりやすい
このことから、計算時間を重視する場合は NSGA 系や MOEA/D を有力候補とし、解の品質や分布の良さをより重視する場合には HypE も選択肢になりえることがわかりました。
全体のまとめ
本記事では、代表的な多目的進化アルゴリズム(NSGA-II、SPEA-II、NSGA-III、HypE、MOEA/D)について、それぞれの特徴と挙動を整理し、複数の観点から比較を行いました。
まず、3目的問題におけるパレートフロントの形状の比較では、NSGA-IIIおよびHypEが分布の均一性および被覆性の面で優れた結果を示しました。これらは参照点や指標に基づいて探索を誘導するため、高次元においても解の分布を維持しやすい特性を持っています。一方でNSGA-IIやSPEA-IIは収束自体は可能であるものの、分布に偏りが生じやすい傾向が確認されました。
次に、目的関数の数を変化させた比較では、目的数の増加に伴う各手法のスケーリング特性の違いが明確に現れました。DTLZ4 のような連続的なパレートフロントでは、目的数が少ない場合は NSGA 系手法が有効でしたが、目的数が増加すると MOEA/D や HypE のような分解ベース・指標ベースの手法が良好な結果を示しました。
一方で DTLZ7 のように不連続かつ局所的な構造を持つ問題では、今回の設定における MOEA/D は不利な結果を示し、SPEA-II が比較的安定した性能を示しました。したがって、手法選択においてはアルゴリズムの分類だけでなく、問題構造とパラメータ設定の相性も重要であるといえます。
計算時間の観点では、NSGA-IIおよびNSGA-IIIは安定した計算コストでバランスの良い手法である一方、MOEA/Dは理論上は軽量であるものの実装や初期化コストに依存する挙動が見られました。HypEは高品質な解が期待できる一方で計算コストが非常に大きく、適用には注意が必要です。SPEA-IIは個体数の増加に伴い計算時間が増大しやすい特性を持っています。
以上の結果から、多目的進化アルゴリズムの選択においては、単に手法の一般的な性能だけでなく、以下の観点を踏まえることが重要です。
- 目的関数の数(少数目的か多数目的か)
- パレートフロントの形状(連続・不連続、均一・非均一)
- 計算コストと許容できる計算時間
実務においては、まず問題の特性を把握した上で、NSGA系をベースラインとして検討し、必要に応じてMOEA/DやHypE、SPEA-IIといった手法を使い分けることが有効です。
本記事の結果が、多目的最適化手法の選択における一つの指針となれば幸いです。
参考文献
[1] K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, "A fast and elitist multiobjective genetic algorithm: NSGA-II," IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182-197, 2002.
[2] E. Zitzler, M. Laumanns, and L. Thiele, "SPEA2: Improving the Strength Pareto Evolutionary Algorithm," TIK-Report, vol. 103, 2001.
[3] J. Bader and E. Zitzler, "HypE: An Algorithm for Fast Hypervolume-Based Many-Objective Optimization," Evolutionary Computation, vol. 19, no. 1, pp. 45-76, 2011.
[4] K. Deb and H. Jain, "An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach—Part I: Solving Problems With Box Constraints," IEEE Transactions on Evolutionary Computation, vol. 18, no. 4, pp. 577-601, 2014.
[5] Q. Zhang and H. Li, "MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition," IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712-731, 2007.
[6] K. Deb, L. Thiele, M. Laumanns, and E. Zitzler, "Scalable Test Problems for Evolutionary Multi-Objective Optimization," TIK-Report, vol. 112, 2001.
